Управление жизненным циклом информационных систем. Информационное обеспечение информационных систем. Разработка информационного обеспечения систем управления предприятием. Информационная база и способы ее организации. Моделирование информационного обеспечения ИС. Моделирование данных
Решение задач и выполнение научно-исследовательских разработок: Отправьте запрос сейчас: irina@bodrenko.org
математика, IT, информатика, программирование, статистика, биостатистика, экономика, психология
Пришлите по e-mail: irina@bodrenko.org описание вашего задания, срок выполнения, стоимость
Управление жизненным циклом информационных систем
Лекция
4
Тема
лекции: «Информационное обеспечение ИС»

- Разработка информационного
обеспечения систем управления предприятием.
- Информационная база и способы ее
организации.
- Моделирование информационного обеспечения
ИС.

- РАЗРАБОТКА ИНФОРМАЦИОННОГО ОБЕСПЕЧЕНИЯ СИСТЕМ
УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ.
Информационная система, оказывая
информационные услуги, преобразует
информационные ресурсы в информационные продукты. Преобразование происходит не
хаотично, а системно. Эту системность позволяет выявить системно-информационный
подход к системе информационного
обеспечения процессов управления на основе
информационных и коммуникационных технологий, результатом которого стало
понятие информационной системы.
Информационная система представляется
как многоцелевая и многофункциональная
кибернетическая система, объединяющая все
обслуживающие информационные и коммуникационные службы предприятия. В службах заняты люди, которые
являются объектами управления со стороны
руководителей предприятия и топ-менеджеров.
Целевое назначение информационной
системы сводится к достижению следующих
целей:
1)
обеспечивать для каждого сотрудника
предприятия возможность пополнения корпоративных знаний (информационных
ресурсов предприятия — ИРП);
2)
сохранять корпоративные знания как
составную часть ИРП;
3)
обеспечивать совместное использование
сотрудниками предприятия текущих и
ретроспективных корпоративных знаний.
Для осуществления этих целей
информационная система, опираясь на свои
подсистемы, должна выполнять следующие функции:
1)
преобразование исходных сообщений
(знаний), поступающих от сотрудников предприятия, включая их смысловую оценку; тиражирование
и ввод в информационно-коммуникационные каналы
предприятия, к виду, удобному для совместного использования;
2)
смысловая обработка (свертывание и
развертывание) первичных сообщений (знаний) для более полного их использования;
3)
формирование и долговременное хранение
информационных ресурсов предприятия в
традиционной и электронной формах;
4)
распространение знаний (текущих и
ретроспективных), хранящихся в
информационном банке предприятия в режимах постоянного оповещения или
справочного обслуживания по запросам.
Таким образом, информационная система —
многоцелевая и многофункциональная
система информационно-коммуникационного
обслуживания, удовлетворяющая информационные и коммуникационные потребности сотрудников
предприятия и внешней среды.
Подсистемами являются все службы
массовой и специальной коммуникации
(информации), в том числе подразделения обучения, хранения, распространения и т.д. Ключевыми
подразделениями в информационной системе
являются службы, применяющие технологии хранения и накопления информации.
Структурно-функциональную схему
информационной системы любого предприятия, включающую в себя все подсистемы с
их взаимосвязями, изобразить невозможно.
Мы ограничимся рассмотрением принципиальной схемы функционирования
информационной системы, показывающей движение
основных информационных потоков на предприятии и взаимодействие участников
этого движения.
Движение информации в информационных
потоках осуществляется следующим
образом. Внешняя среда служит объектом познания, которое осуществляется
сотрудником предприятия, выступающим в
качестве коммуниканта. Для того чтобы
сделать свои знания доступными для всех работников предприятия,
сотрудник должен оформить свои знания в виде, удобном для ознакомления, и направить в службу обработки
информации.
Служба обработки информации в
соответствии со своим алгоритмом работы
и указаниями системы управления (СУ) выбирает дальнейшее направление движения
созданного документа. Если содержание документа признается необходимым
предприятию, коммуникант приобретает
статус элемента информационной системы, а
документ признается полезным информационным ресурсом (ИР).
Службы обработки располагают
необходимыми аппаратно-программными
средствами для соответствующей автоматической и
автоматизированной обработки и тиражирования принятых документов,
которые осуществляются в соответствии с профессиональными знаниями сотрудников
этой службы и указаниями органа управления. В результате обработки документов в
этих службах появляются ИР, доступные для общественного пользования.
Информационные ресурсы могут
представляться в виде традиционных (на
бумаге) и электронных (гипертекст, видео, звук,
изображение) мультимедиа-документов. Они могут быть как доступными
к ознакомлению (текущая память),
так и ограниченно доступными
(ретроспективная память).
Информационные ресурсы предприятия (ИРП) совместно с личностными формируют
виртуальную среду предприятия. Если ИРП
оказываются значимыми, то происходят изменения в структуре предприятия. Ради
этих изменений и создается информационная система, которая увеличивает скорость
адаптации предприятия к изменению внешних воздействий, поступающих из
окружающей среды. Информационная система осуществляет избирательное накопление
индивидуального знания, эмоционального настроения и управляющего стимула, зарождающегося у коммуниканта.
Обобществленная информация начинает
циркулировать в контурах предприятия, достигая сотрудников предприятия и формируя корпоративный интеллект. В случае
если ИР не оказывает никакого воздействия на текущую память предприятия, то он
попадает в архив (ретроспективная память
системы) и ожидает момента своей актуализации.
Другой информационный поток формируется
службой публикации. Вновь появившийся ИР
является объектом изучения сотрудниками службы публикации, которые в
соответствии со своими профессиональными
знаниями и указаниями системы управления (СУ) формируют посреднические продукты (П),
например каталоги, рефераты, списки и
т.д. После чего служба осуществляет
доставку этой информации и самого ИР до реципиента. Так как
распространение ИР представляет собой коммуникационную услугу, то его можно считать
посредническим продуктом.
Следует отметить, что непосредственное
взаимодействие сотрудников предприятия и
ИР исключено, так как осуществляется
контроль над процессами доступа и формирования ИРП со стороны предприятия, которое и является владельцем
информационных ресурсов. Это ограничение не распространяется на
межличностную коммуникацию сотрудников
предприятия. В результате изучения ИРП сознание реципиента обогащается новыми знаниями, которые проявляются в ходе
практического воздействия на внешнюю среду (материальная, предметно-преобразовательная,
социально-политическая деятельность). Таким образом, происходит увеличение нематериальных активов
предприятия путем обмена и накопления информационных ресурсов.
Информационные потоки предприятия можно
представить связанными с двумя видами
событий: плановыми и внезапными.
Плановые события являются регулярными,
которые сами по себе являются процессом,
и нерегулярными, наступление которых можно предвидеть. По отношению к таким
событиям реакция предприятия предусмотрена и однозначно определена. Скорость
ликвидации внезапных событий зависит от
гибкости и скорости реакции предприятия, которые, в свою очередь, зависят от
степени автоматизации процессов обработки
информации и уровня применения информационных технологий.
Если в традиционной модели ведения
бизнеса упор делается на отработку событий первого типа (плановых), то в
современной модели — событий второго
типа (внезапных). Конкурентное преимущество предприятия зависит от наилучшего
соотношения этих составляющих.
Информационную структуру любого
предприятия можно представить с помощью нескольких уровней. Степень
востребованности технологий напрямую связана с
уровнем организационной зрелости предприятия.
Для идеальной компании, которая
находится на высшем уровне организационного развития, все службы представляют
собой единый интегрированный комплекс, являющийся одним из основных элементов электронной нервной системы. Системы
управления взаимодействием с клиентами (CRM) дают возможность оперативно учесть
их пожелания и требования, а системы
управления цепочками поставок (SCM) — получить реакцию на эти требования.
Система планирования ресурсов предприятия (ERP) обеспечивает как краткосрочное,
так и стратегическое планирование деятельности компании и последующее
управление.
Для того чтобы взаимодействие систем
управления предприятия было наиболее эффективным, все они пронизаны
«единым стержнем» — системой управления
знаниями (КМ), которая обеспечивает своевременную доставку информации, а также
средства для ее обработки, анализа и
принятия решений, с использованием систем
анализа данных (Business Intelligence — BI).
Кроме внутренних связей, интеграция
приложений масштаба предприятия
обеспечивается и благодаря повсеместному использованию средств электронной
коммерции (E-commerce)
и Интернет-технологий.
Использование единой информационной
среды не только повысит эффективность бизнеса, но и создаст предпосылки
для стандартизации процессов и
технологий. Это, в свою очередь, повысит надежность работы и совместимость
используемых технологий и решений, а
также позволит наладить правильный процесс использования этой информации.
- ИНФОРМАЦИОННАЯ
БАЗА И СПОСОБЫ ЕЕ ОРГАНИЗАЦИИ.
Информационное обеспечение ИС является
средством для решения следующих задач:
1)
однозначного и экономичного
представления информации в системе (на основе кодирования объектов);
2)
организации процедур анализа и
обработки информации с учетом характера связей между объектами (на основе
классификации объектов);
3)
организации взаимодействия
пользователей с системой (на основе экранных форм ввода-вывода данных);
4)
обеспечения эффективного использования
информации в контуре управления деятельностью объекта автоматизации (на основе
унифицированной системы документации).
Информационное обеспечение ИС
включает два комплекса: внемашинное
информационное обеспечение (классификаторы технико-экономической
информации, документы, методические инструктивные материалы) и внутримашинное информационное обеспечение
(макеты/экранные формы для ввода первичных данных в ЭВМ или вывода результатной
информации, структуры информационной базы: входных, выходных файлов, базы
данных).

К информационному обеспечению
предъявляются следующие общие требования:
- информационное обеспечение должно
быть достаточным для поддержания всех автоматизируемых функций объекта;
- для кодирования информации должны
использоваться принятые у заказчика классификаторы;
-
для кодирования входной и выходной информации, которая используется на
высшем уровне управления, должны быть использованы классификаторы этого уровня;
- должна быть обеспечена совместимость
с информационным обеспечением систем, взаимодействующих с разрабатываемой
системой;
- формы документов должны отвечать
требованиям корпоративных стандартов заказчика (или унифицированной системы
документации );
- структура документов и экранных форм
должна соответствовать характеристиками терминалов на рабочих местах конечных
пользователей;
- графики формирования и содержание
информационных сообщений, а также используемые аббревиатуры должны быть
общеприняты в этой предметной области и согласованы с заказчиком;
- в ИС должны быть предусмотрены
средства контроля входной и результатной информации, обновления данных в
информационных массивах, контроля целостности информационной базы, защиты от
несанкционированного доступа.
Информационное обеспечение ИС можно
определить как совокупность единой системы классификации, унифицированной
системы документации и информационной базы.
2.1.
Внемашинное
информационное обеспечение.
Основные понятия классификации
технико-экономической информации.
Для того чтобы обеспечить эффективный
поиск, обработку на ЭВМ и передачу по каналам связи технико-экономической
информации, ее необходимо представить в цифровом виде. С этой целью ее нужно
сначала упорядочить (классифицировать), а затем формализовать (закодировать) с
использованием классификатора.
Классификация – это разделение
множества объектов на подмножества по их сходству или различию в соответствии с
принятыми методами.
Классификация фиксирует закономерные
связи между классами объектов. Под объектом понимается любой предмет, процесс,
явление материального или нематериального свойства. Система классификации
позволяет сгруппировать объекты и выделить определенные классы, которые будут
характеризоваться рядом общих свойств.
Таким образом, совокупность правил распределения
объектов множества на подмножества называется системой классификации.
Свойство или характеристика объекта
классификации, которое позволяет установить его сходство или различие с другими
объектами классификации, называется признаком классификации.
ПРИМЕР.
Например, признак «роль предприятия-партнера в отношении
деятельности объекта автоматизации» позволяет разделить все предприятия на две
группы (на два подмножества): «поставщики» и «потребители».
Множество или подмножество,
объединяющее часть объектов классификации по одному или нескольким признакам,
носит название классификационной группировки.
Классификатор —
это документ, с помощью которого осуществляется формализованное описание
информации в ИС, содержащей наименования объектов, наименования
классификационных группировок и их кодовые обозначения .
По сфере действия выделяют следующие
виды классификаторов: международные,
общегосударственные (общесистемные), отраслевые и локальные классификаторы.
Международные классификаторы
входят в состав Системы международных экономических стандартов (СМЭС) и
обязательны для передачи информации между организациями разных стран мирового
сообщества.
Общегосударственные (общесистемные) классификаторы,
обязательны для организации процессов передачи и обработки информации между
экономическими системами государственного уровня внутри страны.
Отраслевые классификаторы используют
для выполнения процедур обработки информации и передачи ее между организациями
внутри отрасли.
Локальные классификаторы используют в
пределах отдельных предприятий.
Каждая система классификации
характеризуется следующими свойствами:
1)
гибкостью системы;
2)
емкостью системы;
3)
степенью заполненности системы.

Гибкость системы
— это способность допускать включение новых признаков, объектов без разрушения
структуры классификатора. Необходимая гибкость определяется временем жизни
системы.
Емкость системы
— это наибольшее количество классификационных группировок, допускаемое в данной
системе классификации.
Степень заполненности системы
определяется как частное от деления фактического количества группировок на
величину емкости системы.
В настоящее время чаще всего
применяются два типа систем классификации: иерархическая
и многоаспектная.
При использовании иерархического метода
классификации происходит «последовательное разделение множества объектов на
подчиненные, зависимые классификационные группировки». Получаемая на основе
этого процесса классификационная схема имеет иерархическую структуру. В ней
первоначальный объем классифицируемых объектов разбивается на подмножества по
какому-либо признаку и детализируется на каждой следующей ступени
классификации. Обобщенное изображение иерархической классификационной схемы
представлено на рисунке 1.
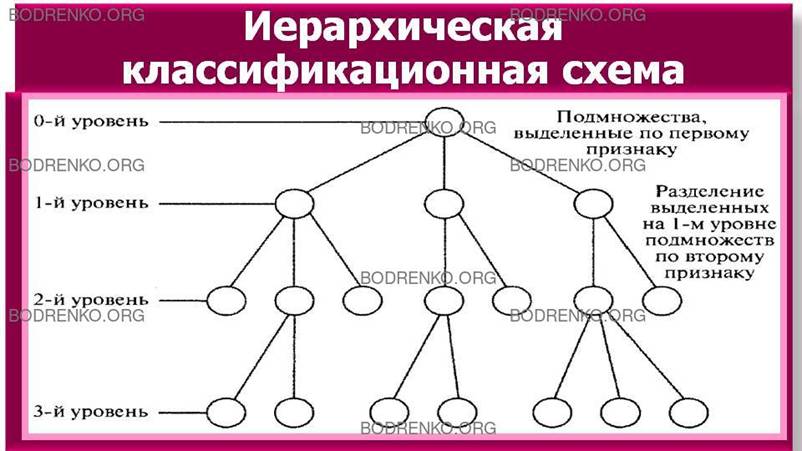
Рисунок
1. Иерархическая классификационная схема.
Характерными особенностями
иерархической системы являются:
1)
возможность использования
неограниченного количества признаков классификации;
2)
соподчиненность признаков
классификации, что выражается разбиением каждой классификационной группировки,
образованной по одному признаку, на множество классификационных группировок по
нижестоящему (подчиненному) признаку.
Таким образом, классификационные схемы,
построенные на основе иерархического принципа, имеют неограниченную емкость,
величина которой зависит от глубины классификации (числа ступеней деления) и
количества объектов классификации, которое можно расположить на каждой ступени.
Количество же объектов на каждой ступени классификации определяется основанием
кода, то есть числом знаков в выбранном алфавите кода. (Например, если алфавит
– двузначные десятичные числа, то можно на одном уровне разместить 100
объектов). Выбор необходимой глубины классификации и структуры кода зависит от
характера объектов классификации и характера задач, для решения которых
предназначен классификатор.
При построении иерархической системы
классификации сначала выделяется некоторое множество объектов, подлежащее
классифицированию, для которого определяются полное множество признаков
классификации и их соподчиненность друг другу, затем производится разбиение
исходного множества объектов на классификационные группировки на каждой ступени
классификации.
К положительным сторонам данной системы
следует отнести логичность, простоту ее построения и удобство логической и
арифметической обработки.
Серьезным недостатком иерархического
метода классификации является жесткость классификационной схемы. Она
обусловлена заранее установленным выбором признаков классификации и порядком их
использования по ступеням классификации. Это ведет к тому, что при изменении
состава объектов классификации, их характеристик или характера решаемых при
помощи классификатора задач требуется коренная переработка классификационной
схемы. Гибкость этой системы обеспечивается только за счет ввода большой
избыточности в ветвях, что приводит к слабой заполненности структуры
классификатора. Поэтому при разработке классификаторов следует учитывать, что
иерархический метод классификации более предпочтителен для объектов с
относительно стабильными признаками и для решения стабильного комплекса задач.
Пример применения иерархической
классификации объектов в корпоративной ИС приведен на рисунке 2. Использование
приведенных моделей позволяет выполнить кодирование информации о
соответствующих объектах, а также использовать процедуры обобщения при
обработке данных (например, при анализе затрат на заработную плату — по
принадлежности работника к определенной службе и пр.).
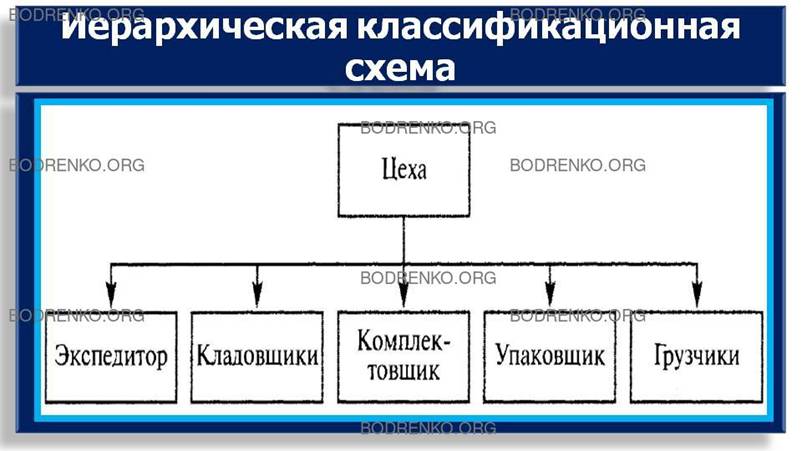
Рисунок
2. Организационная структура подразделения предприятия-цеха отгрузки.
Недостатки, отмеченные в иерархической
системе, отсутствуют в других системах, которые относятся к классу многоаспектных систем классификации.
Аспект —
точка зрения на объект классификации, который характеризуется одним или несколькими
признаками.
Многоаспектная система — это система
классификации, которая использует параллельно несколько независимых признаков
(аспектов) в качестве основания классификации.
Существуют два типа многоаспектных
систем: фасетная и дескрипторная.
Фасет — это аспект классификации, который
используется для образования независимых классификационных группировок.
Дескриптор — ключевое слово, определяющее
некоторое понятие, которое формирует описание объекта и дает принадлежность
этого объекта к классу, группе и т.д.
Под фасетным методом классификации
понимается «параллельное разделение множества объектов на независимые
классификационные группировки».
При этом методе классификации заранее
жесткой классификационной схемы и конечных группировок не создается.
Разрабатывается лишь система таблиц признаков объектов классификации,
называемых фасетами. При необходимости создания классификационной группировки
для решения конкретной задачи осуществляется выборка необходимых признаков из
фасетов и их объединение в определенной последовательности. Общий вид фасетной
классификационной схемы представлен на рисунке 3.
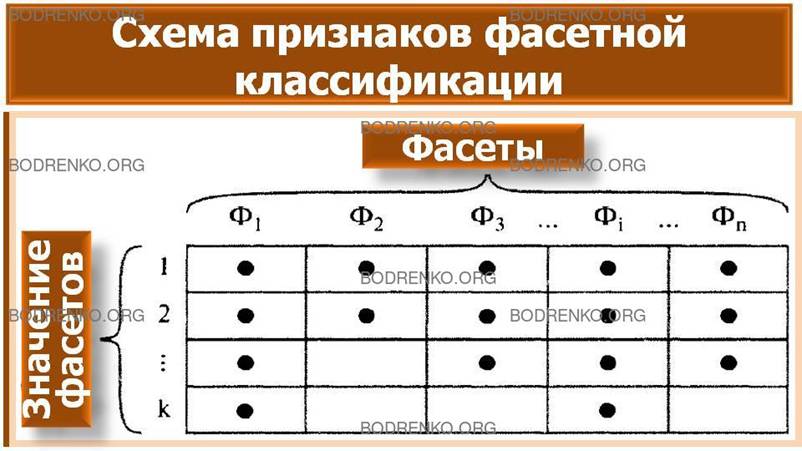
Рисунок
3. Схема признаков фасетной классификации.
Внутри фасета значения признаков могут
просто перечисляться по некоторому порядку или образовывать сложную
иерархическую структуру, если существует соподчиненность выделенных признаков.
К преимуществам данной системы следует
отнести большую емкость системы и высокую степень гибкости, поскольку при
необходимости можно вводить дополнительные фасеты и изменять их место в
формуле. При изменении характера задач или характеристик объектов классификации
разрабатываются новые фасеты или дополняются новыми признаками уже существующие
фасеты без коренной перестройки структуры всего классификатора.
К недостаткам, характерным для данной
системы, можно отнести сложность структуры и низкую степень заполненности
системы.
В современных классификационных схемах
часто одновременно используются оба метода классификации. Это снижает влияние
недостатков методов классификации и расширяет возможность использования
классификаторов в информационном обеспечении управления.
ПРИМЕР.
В качестве примера использования
комбинированных схем классификации в корпоративных ИС можно привести следующую
модель описания продукции предприятия.
Правила классификации продукции.
Принята классификация выпускаемой
продукции по следующему ряду уровней
Иерархическая классификация:
- семейство продуктов;
- группа продуктов;
- серия продуктов.
Однако эта система классификации не
обеспечивает идентификацию любого выпускаемого изделия.
Для каждой единицы продукта должны
указываться следующие атрибуты (Фасеты).
Фасетная классификация:
- код серии продукта;
- конфигурационные параметры;
- свойства.
Код серии продукта – алфавитно-цифровой код, однозначно
идентифицирующий отдельный продукт.
Конфигурационные параметры – свойства,
значения которых могут быть различными в зависимости от потребностей
пользователей.
Свойства – предопределенные характеристики
отдельных продуктов, которые не могут меняться для одного и того же продукта.
Рассмотренные выше системы
классификации хорошо приспособлены для организации поиска с целью последующей
логической и арифметической обработки информации на ЭВМ, но лишь частично
решают проблему содержательного поиска информации при принятии управленческих
решений.
Для поиска показателей и документов по
набору содержательных признаков используется информационный язык дескрипторного
типа, который характеризуется совокупностью терминов (дескрипторов) и набором
отношений между терминами.
Содержание документов или показателей
можно достаточно полно и точно отразить с помощью списка ключевых слов —
дескрипторов.
Дескриптор — это термин естественного
языка (слово или словосочетание), используемый при описании документов или
показателей, который имеет самостоятельный смысл и неделим без изменения своего
значения.
Для того чтобы обеспечить точность и
однозначность поиска с помощью дескрипторного языка, необходимо предварительно
определить все постоянные отношения между терминами: родовидовые, отношения
синонимии, омонимии и полисемии, а также ассоциативные отношения.
Все выделенные отношения явно
описываются в систематическом словаре
понятий — тезаурусе, который разрабатывается с целью проведения
индексирования документов, показателей и информационных запросов.
2.2.
Кодирование технико-экономической
информации.
Для полной формализации информации
недостаточно простой классификации, поэтому проводят следующую процедуру —
кодирование.
Кодирование — это процесс присвоения условных
обозначений объектам и классификационным группам по соответствующей системе
кодирования.
Кодирование реализует перевод
информации, выраженной одной системой знаков, в другую систему, то есть перевод
записи на естественном языке в запись с помощью кодов. Система кодирования —
это совокупность правил обозначения объектов и группировок с использованием
кодов.
Код — это условное обозначение объектов
или группировок в виде знака или группы знаков в соответствии с принятой
системой.
Код базируется на определенном алфавите
(некоторое множество знаков). Число знаков этого множества называется
основанием кода.
Различают следующие типы алфавитов: цифровой, буквенный и смешанный.
Код характеризуется следующими параметрами:
- длиной;
- основанием
кодирования;
- структурой
кода, под которой понимают распределение знаков по признакам и объектам
классификации;
- степенью
информативности, рассчитываемой как частное от деления общего количества
признаков на длину кода;
- коэффициентом
избыточности, который определяется как отношение максимального количества
объектов к фактическому количеству объектов.

К методам кодирования предъявляются
определенные требования:
1)
код должен осуществлять идентификацию
объекта в пределах заданного множества объектов классификации;
2)
желательно предусматривать
использование в качестве алфавита кода десятичных цифр и букв;
3)
необходимо обеспечивать по возможности
минимальную длину кода и достаточный резерв незанятых позиций для кодирования
новых объектов без нарушения структуры классификатора.
Методы кодирования могут носить
самостоятельный характер – регистрационные
методы кодирования, или быть основанными на предварительной классификации
объектов – классификационные методы
кодирования.

Регистрационные методы кодирования
бывают двух видов: порядковый и серийно-порядковый.
В первом случае кодами служат числа натурального ряда. Каждый из объектов
классифицируемого множества кодируется путем присвоения ему текущего
порядкового номера. Данный метод кодирования обеспечивает довольно большую
долговечность классификатора при незначительной избыточности кода. Этот метод
обладает наибольшей простотой, использует наиболее короткие коды и лучше
обеспечивает однозначность каждого объекта классификации. Кроме того, он
обеспечивает наиболее простое присвоение кодов новым объектам, появляющимся в
процессе ведения классификатора. Существенным недостатком порядкового метода
кодирования является отсутствие в коде какой-либо конкретной информации о
свойствах объекта, а также сложность машинной обработки информации при
получении итогов по группе объектов классификации с одинаковыми признаками.
В серийно-порядковом методе кодирования
кодами служат числа натурального ряда с
закреплением отдельных серий этих чисел (интервалов натурального ряда) за объектами
классификации с одинаковыми признаками. В каждой серии, кроме кодов
имеющихся объектов классификации, предусматривается определенное количество
кодов для резерва.
Классификационные коды используют для
отражения классификационных взаимосвязей объектов и группировок и применяются в
основном для сложной логической обработки экономической информации.
Группу классификационных систем
кодирования можно разделить на две подгруппы в зависимости от того, какую
систему классификации используют для упорядочения объектов: системы последовательного кодирования и
параллельного кодирования.
Последовательные системы кодирования
характеризуются тем, что они базируются на предварительной классификации по
иерархической системе. Код объекта классификации образуется с
использованием кодов последовательно расположенных подчиненных группировок,
полученных при иерархическом методе кодирования. В этом случае код нижестоящей
группировки образуется путем добавления соответствующего количества разрядов к
коду вышестоящей группировки.
Параллельные системы кодирования
характеризуются тем, что они строятся на основе использования фасетной системы
классификации и коды группировок по фасетам формируются независимо друг от
друга.
В параллельной системе кодирования
возможны два варианта записи кодов объекта:
- Каждый фасет и признак внутри
фасета имеют свои коды, которые включаются в состав кода объекта.
Такой способ записи удобно применять тогда, когда объекты характеризуются
неодинаковым набором признаков. При формировании кода какого-либо объекта
берутся только необходимые признаки.
- Для
определения групп объектов выделяется фиксированный набор признаков и
устанавливается стабильный порядок их следования, то есть устанавливается
фасетная формула. В этом случае не надо каждый раз указывать, значение
какого из признаков приведено в определенных разрядах кода объекта.
Параллельный метод кодирования имеет
ряд преимуществ. К достоинствам рассматриваемого метода следует отнести
гибкость структуры кода, обусловленную независимостью признаков, из кодов
которых строится код объекта классификации. Метод позволяет использовать при
решении конкретных технико-экономических и социальных задач коды только тех
признаков объектов, которые необходимы, что дает возможность работать в каждом
отдельном случае с кодами небольшой длины. При этом методе кодирования можно
осуществлять группировку объектов по любому сочетанию признаков. Параллельный
метод кодирования хорошо приспособлен для машинной обработки информации. По
конкретной кодовой комбинации легко узнать, набором каких характеристик
обладает рассматриваемый объект. При этом из небольшого числа признаков можно
образовать большое число кодовых комбинаций. Набор признаков при необходимости
может легко пополняться присоединением кода нового признака. Это свойство
параллельного метода кодирования особенно важно при решении
технико-экономических задач, состав которых часто меняется.
Наиболее сложными вопросами, которые
приходится решать при разработке классификатора, являются выбор методов
классификации и кодирования и выбор системы признаков классификации. Основой
классификатора должны быть наиболее существенные признаки классификации,
соответствующие характеру решаемых с помощью классификатора задач. При этом
данные признаки могут быть или соподчиненными, или несоподчиненными. При
соподчиненных признаках классификации и стабильном комплексе задач, для решения
которых предназначен классификатор, целесообразно использовать иерархический
метод классификации, который представляет собой последовательное разделение
множества объектов на подчиненные классификационные группировки. При
несоподчиненных признаках классификации и при большой динамичности решаемых
задач целесообразно использовать фасетный метод классификации.
Важным вопросом является также
правильный выбор последовательности использования признаков классификации по
ступеням классификации при иерархическом методе классификации. Критерием при
этом является статистика запросов к классификатору. В соответствии с этим
критерием на верхних ступенях классификации в классификаторе должны
использоваться признаки, к которым будут наиболее частые запросы. По этой же
причине на верхних ступенях классификации выбирают наименьшее основание кода.
2.3.
Понятие унифицированной системы
документации.
Основной компонентой внемашинного
информационного обеспечения ИС является система документации, применяемая в
процессе управления экономическим объектом. Под документом понимается
определенная совокупность сведений, используемая при решении
технико-экономических задач, расположенная на материальном носителе в
соответствии с установленной формой.
Система документации — это совокупность
взаимосвязанных форм документов, регулярно используемых в процессе управления
экономическим объектом.
Отличительной особенностью системы
экономической документации является большое разнообразие видов документов.
Существующие системы документации,
характерные для неавтоматизированных ИС, отличаются большим количеством разных
типов форм документов, большим объемом потоков документов и их запутанностью,
дублированием информации в документах и работ по их обработке и, как следствие,
низкой достоверностью получаемых результатов.
Для того чтобы упростить систему
документации, используют следующие два подхода:
1)
проведение унификации и стандартизации
документов;
2)
введение безбумажной технологии,
основанной на использовании электронных документов и новых информационных
технологий их обработки.
Унификация документов выполняется путем
введения единых форм документов. Таким образом, вводится единообразие в
наименования показателей, единиц измерения и терминов, в результате чего
получается унифицированная система документации.
Унифицированная система документации
(УСД) — это рационально организованный комплекс взаимосвязанных документов,
который отвечает единым правилам и требованиям и содержит информацию,
необходимую для управления некоторым экономическим объектом.
По уровням управления, они делятся на межотраслевые системы документации,
отраслевые и системы документации локального уровня, т. е. обязательные для
использования в рамках предприятий или организаций.

Любой тип УСД должен удовлетворять
следующим требованиям:
1)
документы, входящие в состав УСД,
должны разрабатываться с учетом их использования в системе взаимосвязанных ЭИС;
2)
УСД должна содержать полную информацию,
необходимую для оптимального управления тем объектом, для которого
разрабатывается эта система;
3)
УСД должна быть ориентирована на
использование средств вычислительной техники для сбора, обработки и передачи
информации;
4)
УСД должна обеспечить информационную
совместимость ЭИС различных уровней;
5)
все документы, входящие в состав
разрабатываемой УСД, и все реквизиты-признаки в них должны быть закодированы с
использованием международных, общесистемных или локальных классификаторов.
2.4.
Внутримашинное информационное
обеспечение ИС.
Основной частью внутримашинного
информационного обеспечения является информационная база.
Информационная база (ИБ) — это совокупность данных,
организованная определенным способом и хранимая в памяти вычислительной системы
в виде файлов, с помощью которых удовлетворяются информационные потребности
управленческих процессов и решаемых задач.
Все файлы ИБ можно классифицировать по
следующим признакам:
- по этапам обработки (входные,
базовые, результатные);
- по типу носителя (на промежуточных
носителях — гибких магнитных дисках и магнитных лентах и на основных носителях
— жестких магнитных дисках, магнитооптических дисках и др.);
- по составу информации (файлы с
оперативной информацией и файлы с постоянной информацией);
- по назначению (по типу функциональных
подсистем);
- по типу логической организации (файлы
с линейной и иерархической структурой записи, реляционные, табличные);
- по способу физической организации
(файлы с последовательным, индексным и прямым способом доступа).
Входные файлы создаются с первичных
документов для ввода данных или обновления базовых файлов.
Файлы с результатной информацией
предназначаются для вывода ее на печать или передачи по каналам связи и не
подлежат долговременному хранению.
К числу базовых файлов, хранящихся в информационной базе, относят основные, рабочие, промежуточные, служебные
и архивные файлы.
Основные файлы должны иметь однородную структуру
записей и могут содержать записи с оперативной
и условно-постоянной информацией.
Оперативные файлы могут создаваться на базе одного или
нескольких входных файлов и отражать информацию одного или нескольких первичных
документов.
Файлы с условно-постоянной информацией
могут содержать справочную, расценочную, табличную и другие виды информации,
изменяющейся в течение года не более чем на 40%, а следовательно, имеющие
коэффициент стабильности не менее 0,6.
Файлы со справочной информацией должны
отражать все характеристики элементов материального производства (материалы,
сырье, основные фонды, трудовые ресурсы и т.п.). Как правило, справочники
содержат информацию классификаторов и дополнительные сведения об элементах материальной
сферы, например о ценах.
Нормативно-расценочные файлы
должны содержать данные о нормах расхода и расценках на выполнение операций и
услуг.
Табличные файлы содержат сведения об экономических
показателях, считающихся постоянными в течение длительного времени (например,
процент удержания, отчисления и пр.).
Плановые файлы содержат плановые показатели,
хранящиеся весь плановый период.
Рабочие файлы создаются для решения конкретных задач
на базе основных файлов путем выборки части информации из нескольких основных
файлов с целью сокращения времени обработки данных.
Промежуточные файлы отличаются от рабочих файлов тем, что
они образуются в результате решения экономических задач, подвергаются хранению
с целью дальнейшего использования для решения других задач. Эти файлы, так же
как и рабочие файлы, при высокой частоте обращений могут быть также переведены
в категорию основных файлов.
Служебные файлы предназначаются для ускорения поиска
информации в основных файлах и включают в себя справочники, индексные файлы и
каталоги.
Архивные файлы содержат ретроспективные данные из основных
файлов, которые используются для решения аналитических, например прогнозных,
задач. Архивные данные могут также использоваться для восстановления
информационной базы при разрушениях.
Организация хранения файлов в
информационной базе должна отвечать следующим требованиям:
1)
полнота хранимой информации для
выполнения всех функций управления и решения экономических задач;
2)
целостность хранимой информации, т. е.
обеспечение непротиворечивости данных при вводе информации в ИБ;
3)
своевременность и одновременность
обновления данных во всех копиях данных;
4)
гибкость системы, т.е. адаптируемость
ИБ к изменяющимся информационным потребностям;
5)
реализуемость системы, обеспечивающая
требуемую степень сложности структуры ИБ;
6)
релевантность ИБ, под которой
подразумевается способность системы осуществлять поиск и выдавать информацию,
точно соответствующую запросам пользователей;
7)
удобство языкового интерфейса,
позволяющее быстро формулировать запрос к ИБ;
8)
разграничение прав доступа, т.е.
определение для каждого пользователя доступных типов записей, полей, файлов и
видов операций над ними.
Существуют следующие способы
организации ИБ:
- совокупность
локальных файлов, поддерживаемых функциональными пакетами прикладных
программ, и
- интегрированная
база данных, основывающаяся на использовании универсальных программных
средств загрузки, хранения, поиска и ведения данных, т.е. системы управления базами данных (СУБД).
Локальные файлы вследствие
специализации структуры данных под задачи обеспечивают, как правило, более
быстрое время обработки данных. Однако недостатки организации локальных файлов,
связанные с большим дублированием данных в информационной системе и, как
следствие, несогласованностью данных в разных приложениях, а также негибкостью
доступа к информации, перекрывают указанные преимущества. Поэтому организация
локальных файлов может применяться только в специализированных приложениях,
требующих очень высокой скорости реакции при импорте необходимых данных.
Интегрированная ИБ, т.е. база данных
(БД) — это совокупность взаимосвязанных, хранящихся вместе данных при такой
минимальной избыточности, которая допускает их использование оптимальным
образом для множества приложений.
Централизация управления данными с
помощью СУБД обеспечивает совместимость этих данных, уменьшение синтаксической
и семантической избыточности, соответствие данных реальному состоянию объекта,
разделение хранения данных между пользователями и возможность подключения новых
пользователей. Но централизация управления и интеграция данных приводят к проблемам
другого характера: необходимости усиления контроля вводимых данных,
необходимости обеспечения соглашения между пользователями по поводу состава и
структуры данных, разграничения доступа и секретности данных.
К концу 1986 года использование языка
SQL в качестве основного для работы с данными в СУБД стало практически
повсеместным. В том же году Американский национальный институт стандартов (ANSI) утвердил
версию языка SQL в качестве международного стандарта обработки данных, что
поставило под угрозу благополучие СУБД, не обладавших поддержкой языка SQL.
Основными способами организации БД
являются создание централизованных и распределенных БД. Основным критерием
выбора способа организации ИБ является достижение минимальных трудовых и
стоимостных затрат на проектирование структуры ИБ, программного обеспечения
системы ведения файлов, а также на перепроектирование ИБ при возникновении
новых задач.
Во всем мире организации накапливают
или уже накопили в процессе своей деятельности большие объемы данных. Эти
коллекции данных хранят в себе большие потенциальные возможности по извлечению
новой, аналитической информации, на основе которой можно и необходимо строить
стратегию фирмы, выявлять тенденции развития рынка, находить новые решения,
обусловливающие успешное развитие в условиях конкурентной борьбы. Для некоторых
фирм такой анализ является неотъемлемой частью их повседневной деятельности, но
большинство, очевидно, только начинает приступать к нему всерьез.
Попытки строить системы принятия
решений, которые обращались бы непосредственно к базам данных систем
оперативной обработки транзакций (OLTP-систем), оказываются в большинстве
случаев неудачными. Во-первых, аналитические запросы «конкурируют» с
оперативными транзакциями, блокируя данные и вызывая нехватку ресурсов.
Во-вторых, структура оперативных данных предназначена для эффективной поддержки
коротких и частых транзакций и в силу этого слишком сложна для понимания
конечными пользователями и, кроме того, не обеспечивает необходимой скорости
выполнения аналитических запросов. В-третьих, в организации, как правило,
функционирует несколько оперативных систем; каждая со своей базой данных. В
этих базах используются различные структуры данных, единицы измерения, способы
кодирования и т.д. Для конечного пользователя (аналитика) задача построения
какого-либо сводного запроса по нескольким подобным базам данных практически
неразрешима.
2.5.
Хранилища
данных.
Для того чтобы обеспечить возможность
анализа накопленных данных, организации стали создавать хранилища данных, которые
представляют собой интегрированные коллекции данных, которые собраны из
различных систем оперативного доступа к данным. Хранилища данных становятся
основой для построения систем принятия решений.

Несмотря на различия в подходах и
реализациях, всем хранилищам данных свойственны следующие общие черты:
- Предметная ориентированность.
Информация в хранилище данных организована в соответствии с основными
аспектами деятельности предприятия (заказчики, продажи, склад и т.п.); это
отличает хранилище данных от оперативной БД, где данные организованы в
соответствии с процессами (выписка счетов, отгрузка товара и т.п.).
Предметная организация данных в хранилище способствует как значительному
упрощению анализа, так и повышению скорости выполнения аналитических
запросов. Выражается она, в частности, в использовании иных, чем в
оперативных системах, схемах организации данных. В случае хранения данных
в реляционной СУБД применяется схема "звезды" (star) или
"снежинки" (snowflake). Кроме того, данные могут храниться в
специальной многомерной СУБД в n-мерных кубах.
- Интегрированность.
Исходные данные извлекаются из оперативных БД, проверяются, очищаются,
приводятся к единому виду, в нужной степени агрегируются (то есть
вычисляются суммарные показатели) и загружаются в хранилище. Такие
интегрированные данные намного проще анализировать.
- Привязка ко времени.
Данные в хранилище всегда напрямую связаны с определенным периодом
времени. Данные, выбранные их оперативных БД, накапливаются в хранилище в
виде «исторических слоев», каждый из которых относится к конкретному
периоду времени. Это позволяет анализировать тенденции в развитии бизнеса.
- Неизменяемость.
Попав в определенный «исторический слой» хранилища, данные уже никогда не
будут изменены. Это также отличает хранилище от оперативной БД, в которой
данные все время меняются, «дышат», и один и тот же запрос, выполненный
дважды с интервалом в 10 минут, может дать разные результаты. Стабильность
данных также облегчает их анализ.
Англоязычный термин «Data Warehousing», который сложно
перевести лаконично на русский язык, означает «создание, поддержку, управление
и использование хранилища данных» и хорошо подтверждает тот факт, что речь идет
о процессе. Цель этого процесса - непрерывная поставка необходимой информации
нужным сотрудникам организации. Этот процесс подразумевает постоянное развитие,
совершенствование, решение все новых задач и практически никогда не кончается,
поэтому его нельзя уместить в более или менее четкие временные рамки, как это
можно сделать для разработки традиционных систем оперативного доступа к данным.
Хранилища данных могут быть разбиты на
два типа: корпоративные хранилища данных
(enterprise data warehouses) и киоски данных (data marts).
Корпоративные хранилища данных
содержат информацию, относящуюся ко всей корпорации и собранную из множества
оперативных источников для консолидированного анализа. Обычно такие хранилища
охватывают целый ряд аспектов деятельности корпорации и используются для
принятия как тактических, так и стратегических решений. Корпоративное хранилище
содержит детальную и обобщающую информацию. Стоимость создания и поддержки
корпоративных хранилищ может быть очень высокой. Обычно их созданием занимаются
централизованные отделы информационных технологий, причем создаются они сверху
вниз, то есть сначала проектируется общая схема, и только затем начинается
заполнение данными. Такой процесс может занимать несколько лет.
Киоски данных содержат подмножество корпоративных
данных и строятся для отделов или подразделений внутри организации. Киоски
данных часто строятся силами самого отдела и охватывают конкретный аспект,
интересующий сотрудников данного отдела. Киоск данных может получать данные из
корпоративного хранилища (зависимый киоск) или, что более распространено,
данные могут поступать непосредственно из оперативных источников (независимый
киоск).
Киоски и хранилища данных строятся по
сходным принципам и используют практически одни и те же технологии.
Основными компонентами хранилища данных
являются следующие:
- оперативные источники данных;
- средства проектирования/разработки;
- средства переноса и трансформации
данных;

- СУБД;
- средства доступа и анализа данных;
- средства администрирования.

Процессы создания, поддержки и
использования хранилищ данных традиционно требовали значительных затрат, что в
первую очередь было вызвано высокой стоимостью доступных на рынке
специализированных инструментов. Эти инструменты практически не интегрировались
между собой, так как были основаны не на открытых и стандартных, а на частных и
закрытых протоколах, интерфейсах и т.д. Сложность и дороговизна делали
практически невозможным построение хранилищ данных в небольших и средних
фирмах, в то время как потребность в анализе данных испытывает любая фирма,
независимо от масштаба.
Корпорация Microsoft давно осознала
важность направления, связанного с хранилищами данных, и необходимость принятия
мер по созданию инструментальной и технологической среды, которая позволила бы
минимизировать затраты на создание хранилищ данных и сделала бы этот процесс
доступным для массового пользователя.
В качестве примера рассмотрим некоторые программные продукты корпорации Microsoft.
ПРИМЕР.
Microsoft SQL Server — система
управления реляционными базами данных (СУРБД), разработанная корпорацией
Microsoft.
Основной используемый язык запросов —
Transact-SQL, создан совместно Microsoft и Sybase. Transact-SQL является
реализацией стандарта ANSI/ISO по структурированному языку запросов (SQL) с
расширениями. Используется для работы с базами данных размером от персональных
до крупных баз данных масштаба предприятия; конкурирует с другими СУБД в этом
сегменте рынка.
Microsoft SQL Server 2012 Parallel Data Warehouse (PDW) — платформа
следующего поколения, построенная с целью ускорения анализа данных и
обеспечения масштабирования хранилища от нескольких терабайт до более чем 6
петабайт данных в одном комплексе.
PDW поставляется в центр обработки
данных как комплекс с заранее установленным программным обеспечением и нацелен
на достижение максимальной производительности.
Благодаря реализованной в PDW обработке
с массовым параллелизмом Massively Parallel Processing (MPP) время выполнения
запросов измеряется минутами, а не часами, как в современных базах данных с
симметричной многопроцессорной обработкой Symmetric Multi-Processing (SMP).
PDW отличается не только
быстродействием и масштабируемостью, но и высокими коэффициентами избыточности
и доступности, заложенными еще на стадии
проектирования. Таким образом, это надежная платформа, которой можно доверить
самые важные для бизнеса данные. Благодаря внятному дизайну платформу просто
освоить и ею легко управлять.
Реализованная в PDW технология PolyBase для анализа данных Hadoop и глубокая
интеграция с инструментами бизнес-аналитики обеспечивают исчерпывающие
возможности для построения полностью готовых к работе решений.
Версия SQL Server 2014 предлагает
для рабочих нагрузок OLTP, хранения данных, бизнес-аналитики и анализа
высокопроизводительную технологию обеспечения безопасности на базе размещения в
памяти, увеличивающую скорость обработки транзакций в 30 раз, а прирост
производительности — в 100 раз.
В SQL
Server 2014 расширяются возможности высокой доступности благодаря наличию
до восьми доступных для чтения баз данных — получателей, повышения уровня
безопасности и масштабируемости, а также реализации гибридного резервного
копирования и аварийного восстановления, как в локальной, так и в облачной
среде.
Например, SQL Server 2014 обеспечивает встроенные в базы данных возможности
обработки транзакций в оперативной памяти, более быстрое получение результатов
запросов и анализа данных с использованием знакомых средств аналитики, а также
позволяет использовать решения для обработки больших данных на корпоративном
уровне. Единая модель программирования и общие средства для всех локальных и
облачных ресурсов позволяют формировать гибридные ИТ-инфраструктуры и сценарии.
Более подробно с продуктами Microsoft SQL
Server можно ознакомиться на сайте.

- МОДЕЛИРОВАНИЕ
ИНФОРМАЦИОННОГО ОБЕСПЕЧЕНИЯ ИС.
3.1. Проектирование экранных форм
электронных документов.
Под электронными формами документов
понимается не изображение бумажного документа, а изначально электронная
(безбумажная) технология работы; она предполагает появление бумажной формы
только в качестве твердой копии документа.
Электронная форма документа (ЭД) — это
страница с пустыми полями, оставленными для заполнения пользователем.
Формы могут допускать различный тип
входной информации и содержать командные кнопки, переключатели, выпадающие меню
или списки для выбора.
Создание форм электронных документов
требует использования специального программного обеспечения.
К недостаткам электронных документов
можно отнести неполную юридическую проработку процесса их утверждения или
подписания.
Технология обработки электронных
документов требует использования специализированного программного обеспечения —
программ управления документооборотом, которые зачастую встраиваются в
корпоративные ИС.
Проектирование форм электронных
документов, т.е. создание шаблона формы с помощью программного обеспечения
проектирования форм, обычно включает в себя выполнение следующих шагов:
1)
создание структуры ЭД — подготовка
внешнего вида с помощью графических средств проектирования;
2)
определение содержания формы ЭД, т.е.
выбор способов, которыми будут заполняться поля. Поля могут быть заполнены
вручную или посредством выбора значений из какого-либо списка, меню, базы
данных;
3)
определения перечня макетов экранных
форм — по каждой задаче проектировщик анализирует «постановку» каждой задачи, в
которой приводятся перечни используемых входных документов с оперативной и
постоянной информацией и документов с результатной информацией;
4)
определение содержания макетов — выполняется
на основе анализа состава реквизитов первичных документов с постоянной и
оперативной информацией и результатных документов.
Работа заканчивается программированием
разработанных макетов экранных форм и их апробацией.
3.2. Моделирование
данных.
Одной из
основных частей информационного обеспечения является информационная база.
Как было определено выше, информационная база (ИБ) представляет собой
совокупность данных, организованную определенным способом и хранимую в памяти
вычислительной системы в виде файлов, с помощью которых удовлетворяются
информационные потребности управленческих процессов и решаемых задач.
Разработка БД выполняется с помощью
моделирования данных.
Цель моделирования данных состоит в
обеспечении разработчика ИС концептуальной схемой базы данных в форме одной
модели или нескольких локальных моделей, которые относительно легко могут быть
отображены в любую систему баз данных. Наиболее распространенным средством
моделирования данных являются диаграммы «сущность-связь» (ERD). С помощью ERD
осуществляется детализация накопителей данных DFD – диаграммы, а также
документируются информационные аспекты бизнес-системы, включая идентификацию
объектов, важных для предметной области (сущностей), свойств этих объектов
(атрибутов) и их связей с другими объектами (отношений).
Базовые понятия ERD.
Сущность (Entity) — множество
экземпляров реальных или абстрактных объектов (людей, событий, состояний, идей,
предметов и др.), обладающих общими атрибутами или характеристиками.
Любой объект системы может быть
представлен только одной сущностью, которая должна быть уникально
идентифицирована. При этом имя сущности должно отражать тип или класс объекта,
а не его конкретный экземпляр (например, АЭРОПОРТ, а не ШЕРЕМЕТЬЕВО).
Каждая сущность должна обладать
уникальным идентификатором. Каждый экземпляр сущности должен однозначно
идентифицироваться и отличаться от всех других экземпляров данного типа
сущности.
Каждая сущность должна обладать
некоторыми свойствами:
- иметь уникальное имя;
- к одному и тому же имени должна
всегда применяться одна и та же интерпретация;
- одна и та же интерпретация не может
применяться к различным именам, если только они не являются псевдонимами;
- иметь один или несколько атрибутов,
которые либо принадлежат сущности, либо наследуются через связь;
- иметь один или несколько атрибутов,
которые однозначно идентифицируют каждый экземпляр сущности.
Каждая сущность может обладать любым
количеством связей с другими сущностями модели.
Связь (Relationship) — поименованная
ассоциация между двумя сущностями, значимая для рассматриваемой предметной
области.
Связь — это ассоциация между
сущностями, при которой каждый экземпляр одной сущности ассоциирован с
произвольным (в том числе нулевым) количеством экземпляров второй сущности, и
наоборот.
Атрибут (Attribute) — любая
характеристика сущности, значимая для рассматриваемой предметной области и
предназначенная для квалификации, идентификации, классификации, количественной
характеристики или выражения состояния сущности.
Атрибут представляет тип характеристик
или свойств, ассоциированных с множеством реальных или абстрактных объектов
(людей, мест, событий, состояний, идей, предметов и т.д.).
Экземпляр атрибута — это определенная
характеристика отдельного элемента множества.
Экземпляр атрибута определяется типом
характеристики и ее значением, называемым значением атрибута. На диаграмме «сущность-связь»
атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр
сущности должен обладать единственным определенным значением для
ассоциированного атрибута.
Метод IDEFI.
Наиболее распространенными методами для
построения ERD-диаграмм являются метод Баркера и метод IDEFI.
Метод Баркера основан на нотации, предложенной
автором, и используется в Case-средстве Oracle Designer.

Метод IDEFI основан на подходе Чена и
позволяет построить модель данных, эквивалентную реляционной модели в третьей
нормальной форме. На основе совершенствования метода IDEFI создана его новая
версия — метод IDEFIX, разработанный с учетом таких требований, как простота
для изучения и возможность автоматизации. IDEFIX-диаграммы используются в ряде
распространенных CASE-средств (в частности, ERwin, Design/IDEF).
В методе IDEFIX сущность является
независимой от идентификаторов или просто независимой, если каждый экземпляр
сущности может быть однозначно идентифицирован без определения его отношений с
другими сущностями. Сущность называется зависимой от идентификаторов или просто
зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения
к другой сущности.

Отображение модели данных в
инструментальном средстве ERwin.
ERwin имеет два уровня представления
модели — логический и физический.
Логический уровень — это абстрактный взгляд на данные,
когда данные представляются так, как выглядят в реальном мире, и могут
называться так, как они называются в реальном мире, например "Постоянный
клиент", "Отдел" или "Фамилия сотрудника". Объекты
модели, представляемые на логическом уровне, называются сущностями и
атрибутами. Логическая модель данных может быть построена на основе другой
логической модели, например на основе модели процессов. Логическая модель
данных является универсальной и никак не связана с конкретной реализацией СУБД.
Физическая модель данных, напротив,
зависит от конкретной СУБД, фактически являясь отображением системного
каталога. В физической модели содержится информация обо всех объектах БД.
Поскольку стандартов на объекты БД не существует (например, нет стандарта на
типы данных), физическая модель зависит от конкретной реализации СУБД.
Следовательно, одной и той же логической модели могут соответствовать несколько
разных физических моделей. Если в логической модели не имеет значения, какой
конкретно тип данных имеет атрибут, то в физической модели важно описать всю информацию
о конкретных физических объектах — таблицах, колонках, индексах, процедурах и
т.д.
1)
Документирование
модели.
Многие СУБД имеют ограничение на
именование объектов (например, ограничение на длину имени таблицы или запрет
использования специальных символов — пробела и т. п.). Зачастую разработчики ИС
имеют дело с нелокализованными версиями СУБД. Это означает, что объекты БД
могут называться короткими словами, только латинскими символами и без
использования специальных символов (т. е. нельзя назвать таблицу, используя
предложение — ее можно назвать только одним словом). Кроме того, проектировщики
БД нередко злоупотребляют «техническими» наименованиями, в результате таблица и
колонки получают наименования типа RTD_324 или CUST_A12 и т.д. Полученную в
результате структуру могут понять только специалисты (а чаще всего — только
авторы модели), ее невозможно обсуждать с экспертами предметной области.
Разделение модели на логическую и физическую позволяет решить эту проблему.
На физическом уровне объекты БД могут
называться так, как того требуют ограничения СУБД.
На логическом уровне можно этим
объектам дать синонимы — имена более понятные неспециалистам, в том числе на
кириллице и с использованием специальных символов.
Например, таблице CUST_A12 может соответствовать
сущность Постоянный клиент. Такое соответствие позволяет лучше документировать
модель и дает возможность обсуждать структуру данных с экспертами предметной
области.
2)
Масштабирование.
Создание модели данных, как правило,
начинается с разработки логической модели. После описания логической модели
проектировщик может выбрать необходимую СУБД, и ERwin автоматически создаст
соответствующую физическую модель. На основе физической модели ERwin может
сгенерировать системный каталог СУБД или соответствующий SQL-скрипт. Этот
процесс называется прямым проектированием (Forward Engineering). Тем самым
достигается масштабируемость — создав одну логическую модель данных, можно
сгенерировать физические модели под любую поддерживаемую ERwin СУБД. С другой
стороны, ERwin способен по содержимому системного каталога или SQL-скрипту
воссоздать физическую и логическую модель данных (Reverse Engineering). На
основе полученной логической модели данных можно сгенерировать физическую
модель для другой СУБД и затем создать ее системный каталог. Следовательно,
ERwin позволяет решить задачу по переносу структуры данных с одного сервера на
другой. Например, можно перенести структуру данных с Oracle на Informix (или
наоборот) или перенести структуру dbf-файлов в реляционную СУБД, тем самым
облегчив переход от файл-серверной к клиент-серверной ИС. Однако, формальный
перенос структуры «плоских» таблиц на реляционную СУБД обычно неэффективен. Для
того чтобы извлечь выгоды от перехода на клиент-серверную технологию, структуру
данных следует модифицировать.
ПРИМЕР.
Новая версия CA ERwin r9.6
В текущем 2015 году компания CA Technologies сообщила об общей
доступности нового пакета моделирования CA ERwin r9.6, в который включены
следующие продукты и редакции:
CA ERwin Data
Modeler;
CA ERwin Data
Modeler Standard Edition;
CA ERwin Data
Modeler Workgroup Edition;

CA ERwin Data
Modeler Navigator Edition;
CA ERwin Data
Modeler Community Edition;
CA ERwin Web
Portal;

Редакция Standard;
Редакция Enterprise;
Редакция Data Governance.

Этот релиз флагманского продукта
компании СА, CA ERwin Data Modeler, включает новую функциональность и основные
усовершенствования в:
Report Designer;
экспорт отчетов PDF;
обновления для поддержки баз данных;
обновленные средства импорта/экспорта
метаданных;
усовершенствования интерфейса
пользователя;
центр оперативной справки и
документации;
а также общие исправления для продукта
и другие элементы сопровождения, опубликованные до этой даты.
Релиз
CA ERwin Web Portal отличает:
- заново спроектированный интерфейс
пользователя (переход от нового интерфейса с «плоским дизайном» к расширенной
поддержке всех средств мультимедиа, включая плитки, сенсорные экраны и
маленькие экраны),
- улучшенное табличное представление
информации,
- упрощенные средства навигации.
Редакция Data Governance, которая
содержит множество новых функций и возможностей, включая бизнес-словарь,
базирующийся на стандарте ISO-11179, семантику и возможности структурирования
данных, автоматически сгенерированные диаграммы архитектуры, универсальное
моделирование данные и оперативное в реальном времени получение информации из
реляционных и больших источников данных.
Таким образом, применяя тот или иной
методологический подход (системный, операционный, объектно-ориентированный и
т.д.), мы строим соответствующую ему модель, на базе которой и ведется создание ИС предприятия.
СПИСОК РЕКОМЕНДОВАННОЙ ЛИТЕРАТУРЫ.
[1] Грекул В.И., Денищенко Г.Н.,
Коровкина Н.Л. Проектирование информационных систем. Курс лекций. Учебное пособие
для студентов вузов, обучающихся по специальностям в области информационных
технологий. – М.: Интернет ун-т Информ.
Технологий, 2005. – 304 с., ил.
[2] Зараменских Е.П. Управление жизненным циклом информационных систем:
Монография – Новосибирск: Издательство ЦРНС, 2014. – 270 с.

[3] Информационные системы в экономике:
Учебник. /Под ред. Г.А. Титоренко. – 2-е изд., перераб. и доп. – М.: ЮНИТИ-ДАНА, 2008. – 463 с.
[4]
Информационные системы и технологии в экономике и управлении: Учебник / Под ред. проф. В.В.
Трофимова. — М.: Высшее образование,
2006.-480 с.
[5] Советов
Б.Я., Цехановский В.В. Информационные технологии: Учебник для вузов – 3-е изд., стер. – М.: Высш. шк., 2006. – 263
с: ил.
