Стандартизация, сертификация и управление качеством ПО. Структурный подход к проектированию программного обеспечения. Методы структурного анализа. Спецификации процессов. Методология SADT. Диаграммы потоков данных (DFD). Модель «сущность-связь». Диаграммы переходов состояний (STD). ER-диаграмма. Правило балансировки
Решение задач и выполнение научно-исследовательских разработок: Отправьте запрос сейчас: irina@bodrenko.org
математика, IT, информатика, программирование, статистика, биостатистика, экономика, психология
Пришлите по e-mail: irina@bodrenko.org описание вашего задания, срок выполнения, стоимость
Стандартизация, сертификация и управление качеством
программного обеспечения
Лекция 4.
Тема лекции: «Структурный подход к проектированию
программного обеспечения».

- Методы
структурного анализа. Спецификации процессов.
- Методология
SADT.
- Диаграммы
потоков данных (DFD).
Модель «сущность-связь».

- МЕТОДЫ
СТРУКТУРНОГО АНАЛИЗА. СПЕЦИФИКАЦИИ ПРОЦЕССОВ.
1.1.
Анализ требований и определение
спецификаций при структурном подходе.
1.1.
На
этом этапе необходимо построить модели ПО во взаимодействии с окружающей средой. Поскольку
разные модели описывают проектируемое программное обеспечение с разных сторон,
рекомендуется использовать сразу несколько моделей и сопровождать их
описаниями. Структурный подход к проектированию
программных продуктов предполагает разработку следующих моделей:
-
диаграмм потоков данных (DFD — Data Flow
Diagrams), описывающих взаимодействие источников и потребителей информации
через процессы, которые должны быть реализованы в системе;
-
диаграмм «сущность—связь» (ERD
Entity-Relationship Diagrams), описывающих базы данных разрабатываемой системы;
-
диаграмм переходов состояний (STD —
State Transition Diagrams), характеризующих поведение системы во времени;
-
функциональных диаграмм (методология
SADT);

-
спецификаций процессов;
-
словаря терминов.

1.2.
Спецификации процессов.
1.2.
Спецификации
процессов могут быть представлены в виде псевдокодов, блок-схем алгоритмов,
Flow-форм, диаграмм Насей – Шнейдермана
или просто краткого текстового описания.
При
структурном программировании различают три вида вычислительного процесса: линейный, разветвленный и циклический.
Линейная
структура
— выполнение операторов последовательно.
Разветвленная
структура
— в зависимости от выполнения некоторого
условия выполняется та или иная последовательность операторов.
Циклическая
структура
— многократное выполнение одинаковой
последовательности операторов.

1.3.
Схемы алгоритмов.
1.3.
Для
изображения схем алгоритмов разработан ГОСТ 19.701—90 (рисунок 1). 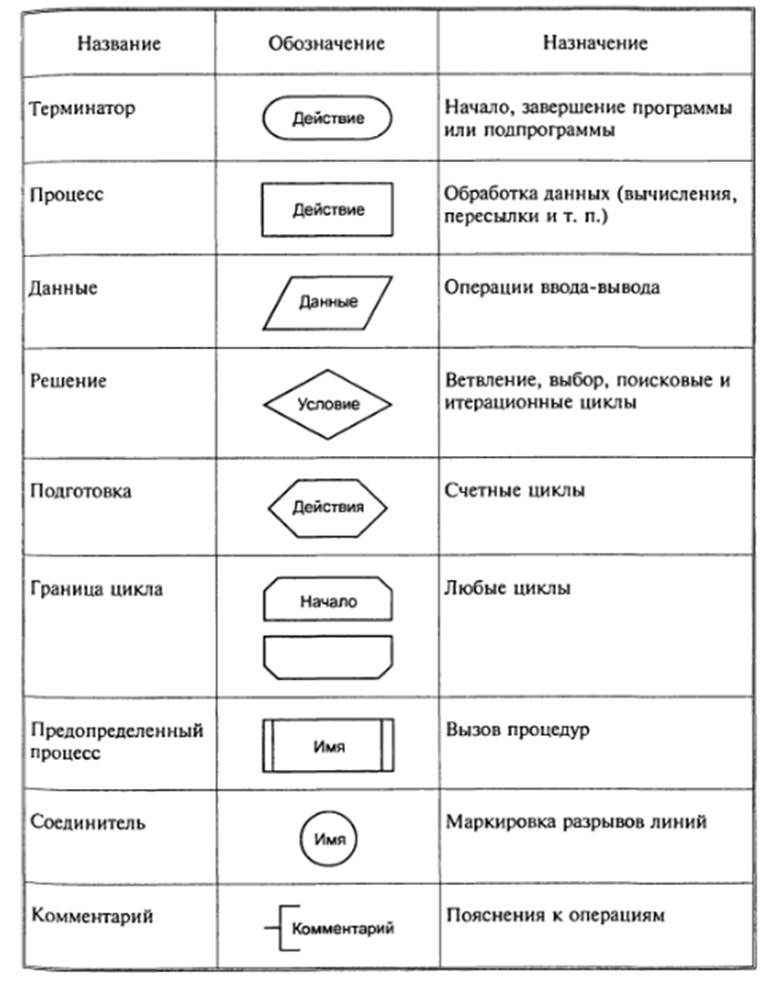
Рисунок 1. Обозначение элементов схем
алгоритмов.
Любой,
сколь угодно сложный, алгоритм можно представить с использованием трех основных
конструкций, которые получили название
базовых:
-
следование. Обозначает
последовательное выполнение действий
(рисунок 2);
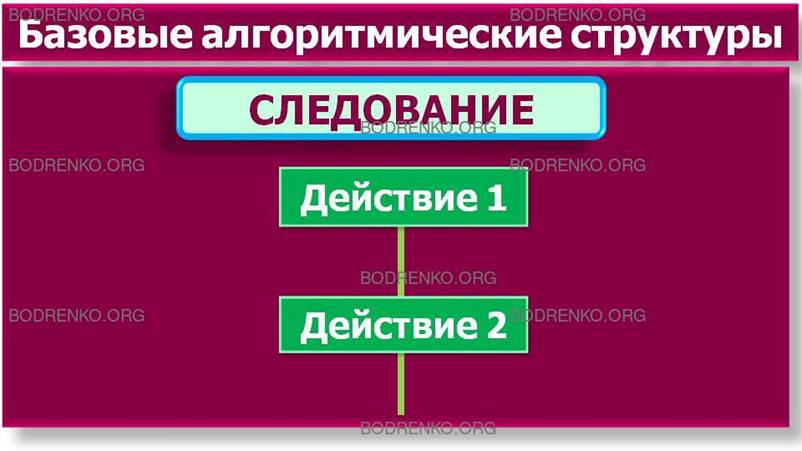
Рисунок 2. Базовые алгоритмические
структуры: следование.
-
ветвление. Соответствует выбору
одного из двух вариантов действий (рисунок 3);
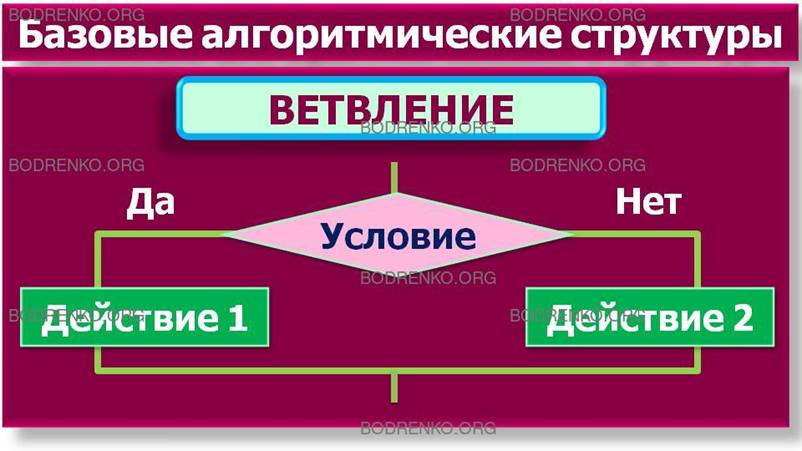
Рисунок 3. Базовые алгоритмические
структуры: ветвление.
-
цикл-пока.
Определяет повторение действий, пока не будет нарушено некоторое условие,
выполнение которого проверяется в начале
цикла (рисунок 4).
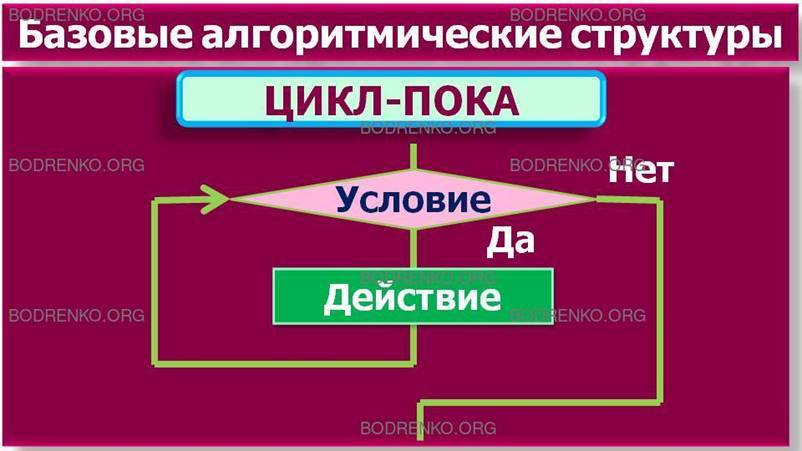
Рисунок 4. Базовые алгоритмические
структуры: цикл-пока.
Помимо
базовых, процедурные языки программирования высокого уровня обычно используют
еще три конструкции, которые можно
составить из базовых:
-
выбор.
Обозначает выбор одного варианта из нескольких в зависимости от значения
некоторой величины (рисунок 5);
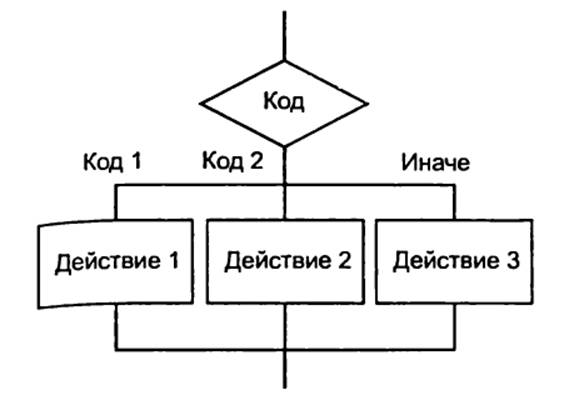
Рисунок 5. Дополнительные структуры
алгоритмов: выбор.
-
цикл-до.
Обозначает повторение некоторых действий до выполнения заданного условия, проверка
которого осуществляется после выполнения
действий в цикле (рисунок 6);
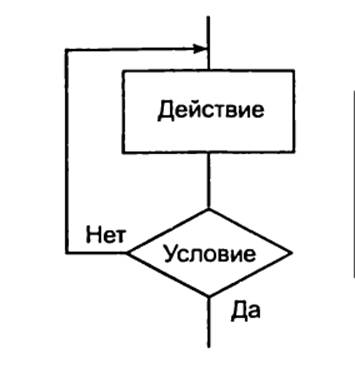
Рисунок
6. Дополнительные структуры алгоритмов: цикл-до.
-
цикл
с заданным числом повторений (счетный цикл). Обозначает повторение некоторых действий
указанное количество раз (рисунок 7).
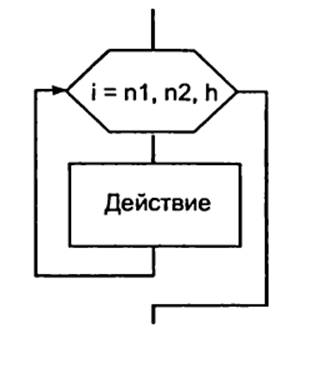
Рисунок 7. Дополнительные структуры
алгоритмов: цикл с заданным числом повторений.

Любая
из дополнительных конструкций легко реализуется с помощью базовых.
ПЕРЕЧИСЛЕННЫЕ
ШЕСТЬ КОНСТРУКЦИЙ БЫЛИ ПОЛОЖЕНЫ В ОСНОВУ
СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ.
1.4.
Псевдокоды.
1.4.
Псевдокод
— формализованное текстовое описание алгоритма
(текстовая нотация).
В литературе были предложены несколько
вариантов псевдокодов. Один из них приведен в таблице (рисунок 8).
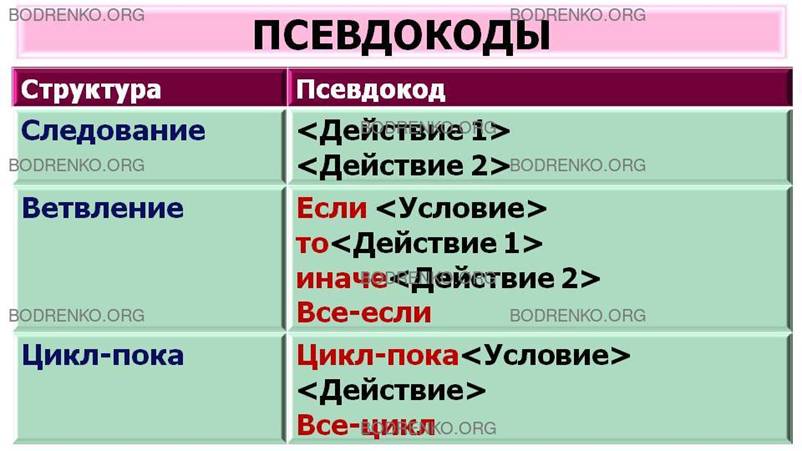
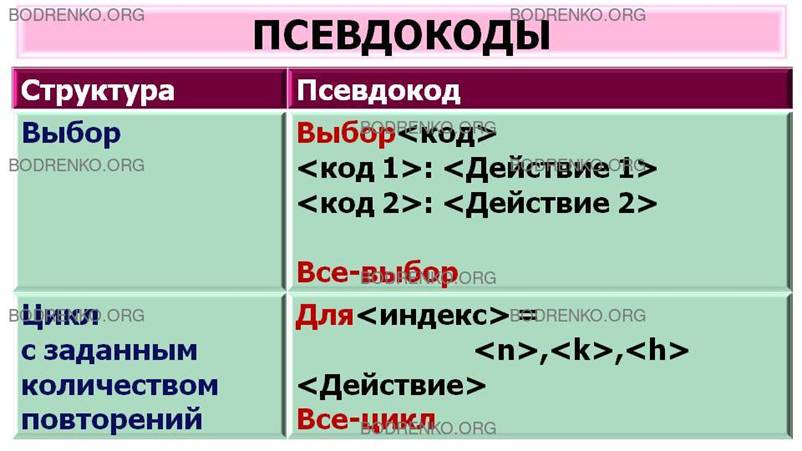

Рисунок 8. Описания псевдокодов.
1.5.
Flow-формы.
1.5.
Flow-формы
представляют собой графическую нотацию описания
структурных алгоритмов, которая иллюстрирует вложенность структур.
Каждый
символ Flow-формы имеет вид прямоугольника и может быть вписан в любой
внутренний прямоугольник любого другого
символа. Нотация Flow-форм приведена на рисунке 9.
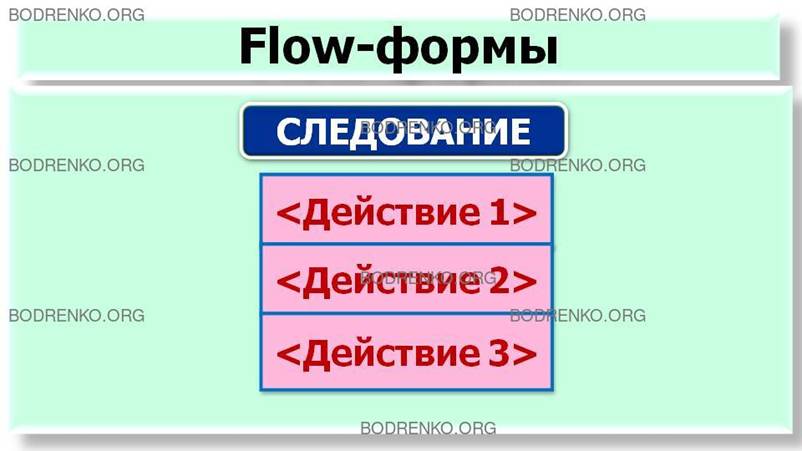

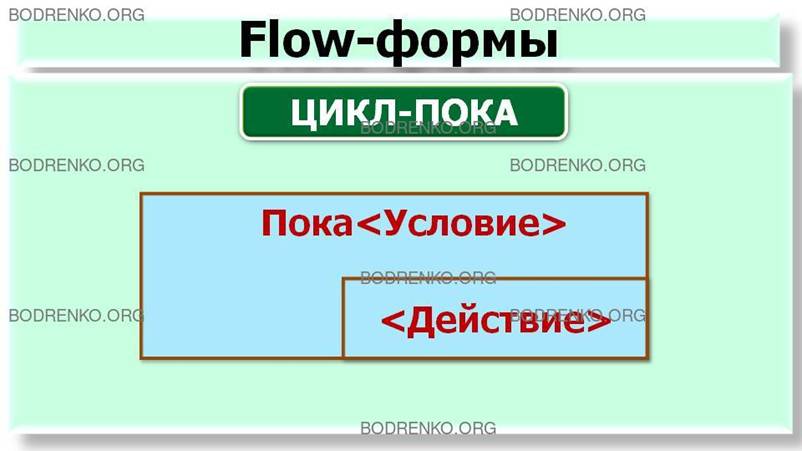

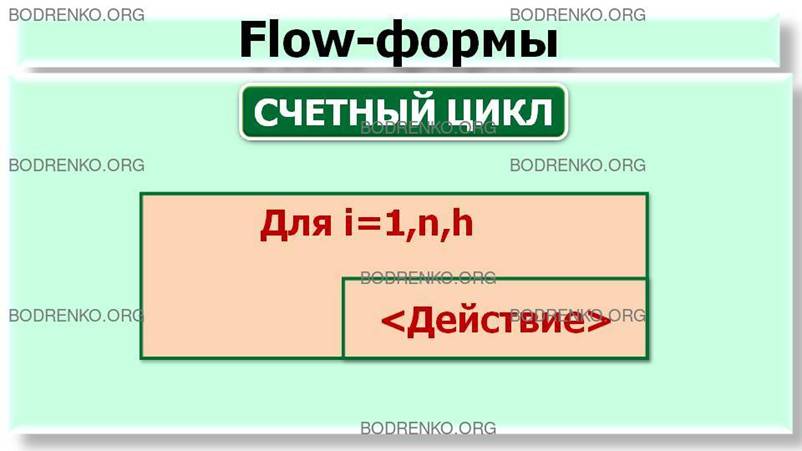
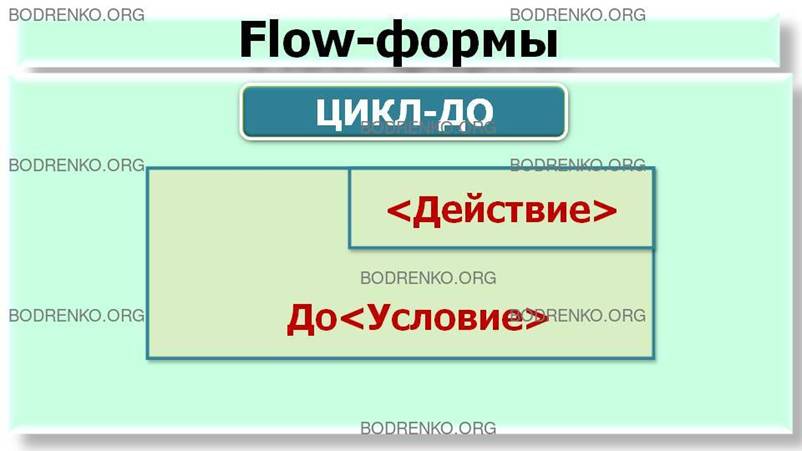
Рисунок
9. Flow-формы для основных конструкций: следование; ветвление; выбор; цикл-пока;
цикл-до; счетный цикл.
1.6.
Диаграммы Насси — Шнейдермана.
1.6.
Диаграммы
Насси — Шнейдермана являются продолжением Flow-форм. Отличие их от Flow-форм
состоит в том, что область обозначения условий изображают в виде треугольников (рисунок
10). Это обозначение обеспечивает большую наглядность представления алгоритма.
При
использовании псевдокодов, Flow-форм и диаграмм Насси — Шнейдермана описать
неструктурный алгоритм невозможно (для
неструктурных передач управления в этих нотациях просто отсутствуют условные
обозначения).
По
сравнению с псевдокодами Flow-формы и диаграммы Насси — Шнейдермана, являясь
графическими, лучше отображают
вложенность конструкций.
Общим
недостатком Flow-форм и диаграмм Насси — Шнейдермана является сложность
построения изображений символов, что затрудняет практическое применение этих
нотаций для описания больших алгоритмов.
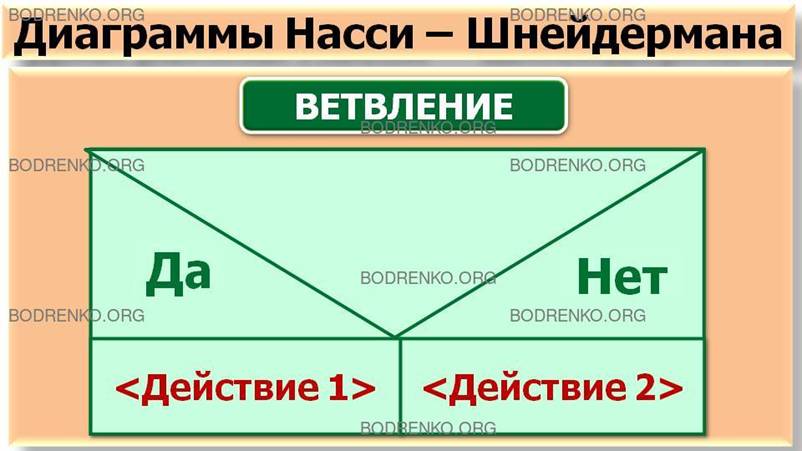
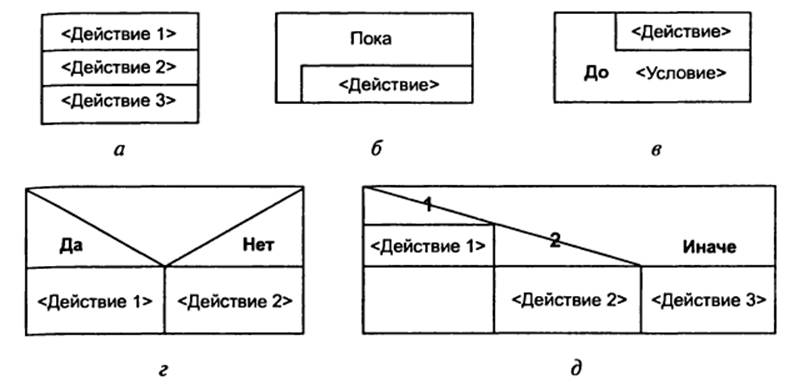
Рисунок
10. Условные обозначения диаграмм Насси — Шнейдермана для основных конструкций: а — следование; б —
цикл-пока; в — цикл-до; г — ветвление; д — выбор.
1.7.
Словарь терминов.
1.7.
Словарь
терминов представляет собой краткое описание основных понятий, используемых при составлении
спецификаций.
Он
предназначен для повышения степени понимания предметной области и исключения риска
возникновения разногласий при обсуждении моделей между заказчиками и
разработчиками.
Обычно
описание термина в словаре выполняют по следующей
схеме:
-
термин;
-
категория (понятие предметной области, элемент данных, условное обозначение и
т. д.);
-
краткое описание.
ПРИМЕР
1.
Термин:
Web-сайт
Категория:
Интернет-программирование
Описание:
Совокупность Web-страниц с повторяющимся дизайном, объединенных по смыслу,
навигационно и физически находящихся на одном сервере.
1.8.
Диаграммы переходов состояний (SDT).
1.8.
SDT демонстрирует
поведение разрабатываемой программной
системы при получении управляющих воздействий (извне).
В
диаграммах такого вида узлы соответствуют состояниям динамической системы, а дуги — переходу
системы из одного состояния в другое.
Узел, из которого выходит дуга, является начальным состоянием, узел, в который дуга
входит, — следующим.
Дуга
помечается именем входного сигнала или события, вызывающего переход, а также сигналом или
действием, сопровождающим переход.
Условные обозначения, используемые при построении
диаграмм переходов состояний, показаны на рисунке 11.

Рисунок
11. Диаграммы переходов состояний: терминальное
состояние; промежуточное состояние;
переход
На
рисунке 12 представлена диаграмма переходов состояний программы, активно не
взаимодействующей с окружающей средой,
которая имеет примитивный интерфейс, производит некоторые вычисления и выводит простой
результат.
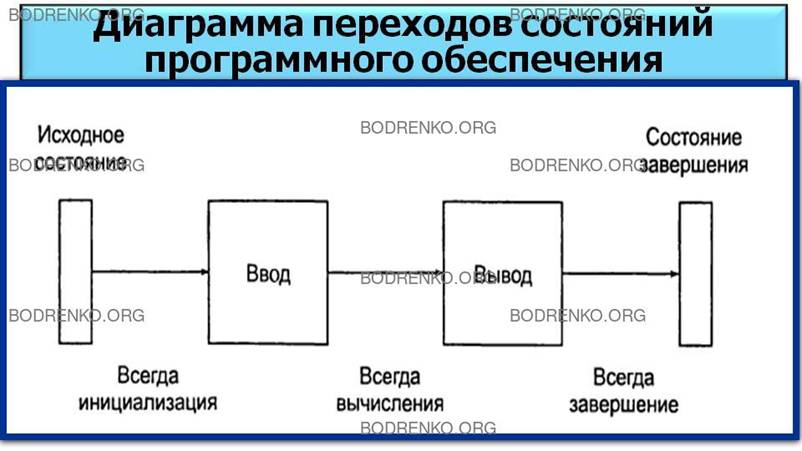
Рисунок
12. Диаграмма переходов состояний программного обеспечения, активно не
взаимодействующего с окружающей средой.
На
рисунке 13 представлена диаграмма переходов торгового автомата, активно взаимодействующего с
покупателем.
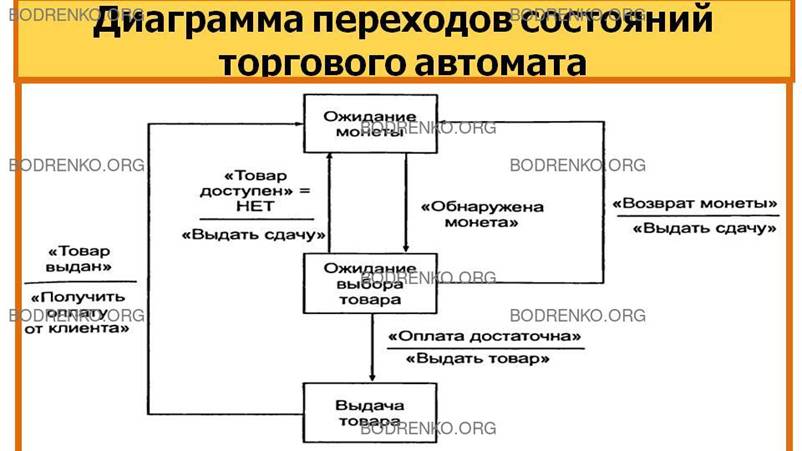
Рисунок 13. Диаграмма переходов
состояний торгового автомата.
2.
МЕТОДОЛОГИЯ
SADT.
2.1. Функциональные
диаграммы.
2.1.
Функциональными
называют диаграммы, в первую очередь отражающие взаимосвязи функций
разрабатываемого программного
обеспечения.
Они
создаются на ранних этапах проектирования систем, для того чтобы помочь
проектировщику выявить основные функции и составные части проектируемой системы
и, по возможности, обнаружить и
устранить существенные ошибки.
Современные
методы структурного анализа и проектирования предоставляют разработчику определенные
синтаксические и графические средства
проектирования функциональных диаграмм информационных систем.
В
качестве примера рассмотрим методологию SADT (Structured
Analysis and Design Technique), предложенную Дугласом Россом. На ее основе
разработана, в частности, известная методология IDEFO (Icam DEFinition).
Методология
SADT представляет собой набор методов, правил и процедур, предназначенных для
построения функциональной модели объекта
каком-либо предметной области.
Функциональная
модель SADT отображает функциональную структуру объекта, т. е. производимые им
действия и связи между этими действиями. Основные элементы этой методологии основываются на следующих концепциях:
-
графическое представление блочного моделирования. На SADT-диаграмме функции
представляются в виде блока, а интерфейсы входа-выхода — в виде дуг,
соответственно входящих в блок и выходящих из него. Интерфейсные дуги отображают
взаимодействие функций друг с другом;
-
строгость и точность отображения.
Правила
SADT включают:
1)
уникальность
меток и наименований;
1)
2)
ограничение
количества блоков на каждом уровне декомпозиции;
2)
3)
синтаксические
правила для графики;
3)
4)
связность
диаграмм;
4)
5)
отделение
организации от функции;
5)
6)
разделение
входов и управлений.
6)
Методология
SADT может использоваться для моделирования
и разработки широкого круга систем, удовлетворяющих определенным требованиям и реализующих
требуемые функции.
В
уже разработанных системах методология SADT может быть использована для анализа
выполняемых ими функций, а также для указания механизмов, посредством которых
они осуществляются.
Диаграммы
— главные компоненты модели, все функции программной системы и интерфейсы на
них представлены как блоки и дуги. Место соединения дуги с блоком определяет
тип интерфейса. Дуга, обозначающая управление, входит в блок сверху, в то время
как информация, которая подвергается обработке,
представляется дугой с левой стороны блока, а результаты обработки — дугами с
правой стороны. Механизм (человек или автоматизированная система), который
осуществляет операцию, представляется в виде дуги, входящей в блок снизу (рисунок
14).
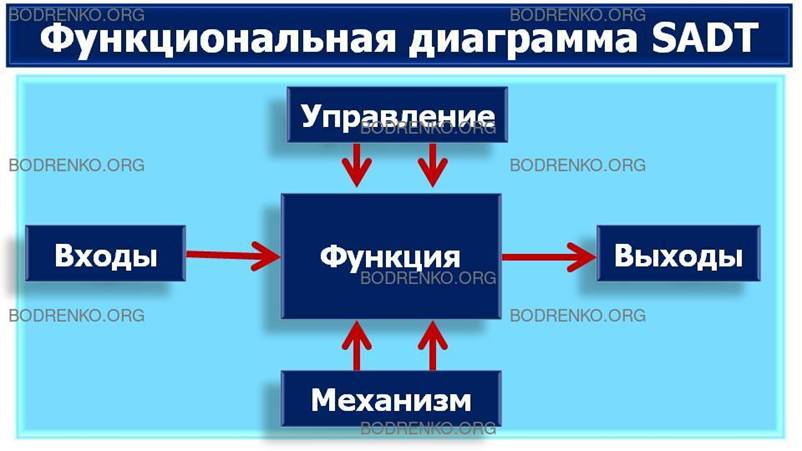
Рисунок 14. Функциональный блок и
интерфейсные дуги.
Блоки
на диаграмме размещают по «ступенчатой» схеме в соответствии с последовательностью их работы
или доминированием, которое понимается
как влияние, оказываемое одним блоком на
другие. В функциональных диаграммах SADT
различают пять типов влияний блоков друг на друга:
-
вход-выход
блока подается на вход блока с меньшим доминированием, т. е. следующего (рисунок 15,
а);
-
управление.
Выход блока используется как управление для блока с меньшим доминированием (рисунок
15, б),
-
обратная
связь по входу. Выход блока подается на вход блока с большим
доминированием (рисунок 15, в);
-
обратная связь по управлению. Выход
блока используется как управляющая информация для блока с большим доминированием (рисунок 15, г);
-
выход-исполнитель. Выход блока
используется как механизм для другого
блока (рисунок 15, д).

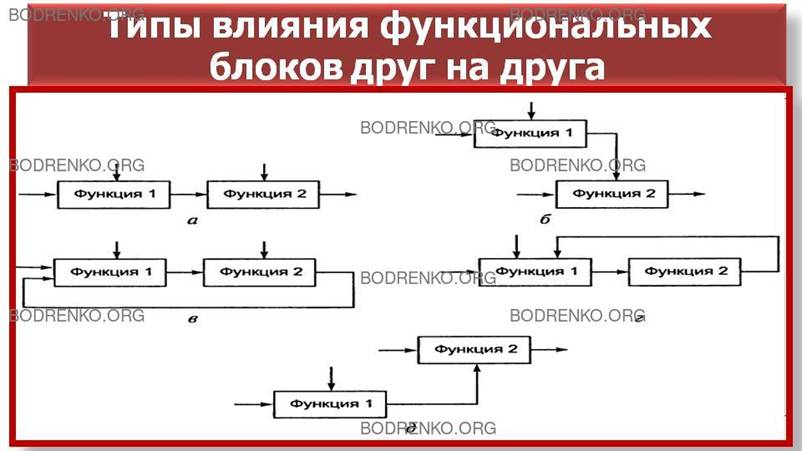
Рисунок
15. Типы влияний блоков: а — вход; б — управление; в — обратная связь по входу;
г – обратная связь по управлению; д — выход-исполнитель.
Одной
из наиболее важных особенностей методологии SADT является постепенное введение
все больших уровней детализации по мере
создания диаграмм, отображающих модель.
На
рисунке 16 приведены четыре диаграммы и их взаимосвязи, показывающие структуру
SADT-модели. Каждый компонент модели
может быть декомпозирован на другой диаграмме. Детальная диаграмма иллюстрирует
внутреннее строение блока «родительской»
диаграммы.
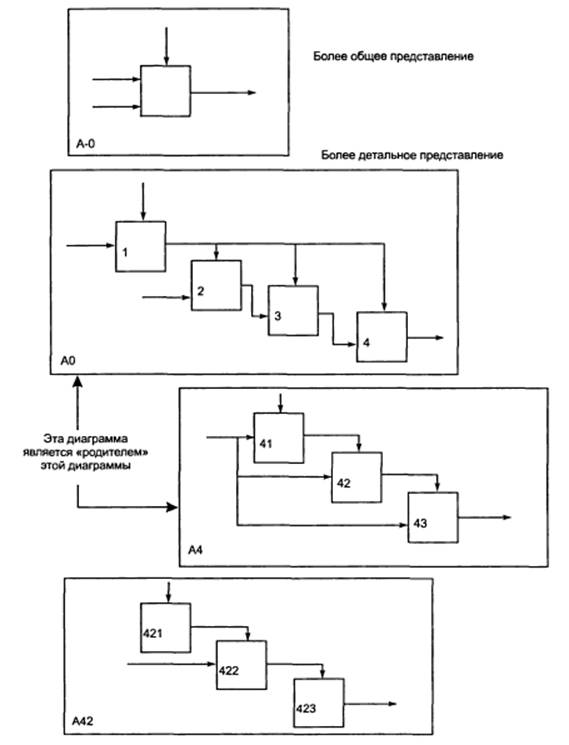
Рисунок 16. Структура SADT-модели.
Декомпозиция диаграмм.
2.2.
Иерархия
диаграмм.
2.2.
Прежде
всего, вся система представляется в виде простейшей компоненты — одного блока и
дуг, представляющих собой интерфейсы с
внешними по отношению к данной системе функциями.
Имя блока является общим для всей системы.
Затем
блок, который представляет систему в целом, детализируется на следующей диаграмме. Он
представляется в виде нескольких блоков,
соединенных интерфейсными дугами. Каждый блок детальной диаграммы представляет
собой подфункцию, границы которой определены интерфейсными дугами. Каждый из
блоков детальной диаграммы может быть также детализирован на следующей в иерархии
диаграмме. На каждом шаге декомпозиции
более общая диаграмма называется родительской для более детальной диаграммы.
Все
диаграммы связывают друг с другом иерархической нумерацией блоков: первый уровень — А0, второй
— A1, A2 и т. п., третий — A11, A12, А13 и т. п., где первые цифры — номер родительского блока, а последняя — номер
конкретного блока детальной диаграммы.
Во
всех случаях каждая подфункция может содержать только те элементы, которые
входят в исходную функцию, причем никакие
из них не могут быть опущены. То есть родительский блок и его интерфейсы
обеспечивают контекст. К нему нельзя ничего добавить, и из него не может быть
ничего удалено.
Дуги,
входящие в блок и выходящие из него на диаграмме верхнего уровня, являются точно
теми же самыми, что и дуги, входящие в диаграмму нижнего уровня и выходящие из
нее, потому что блок и диаграмма
представляют одну и ту же часть системы.
На
рисунках 17 – 19 представлены различные
варианты выполнения функций и соединения
дуг с блоками.
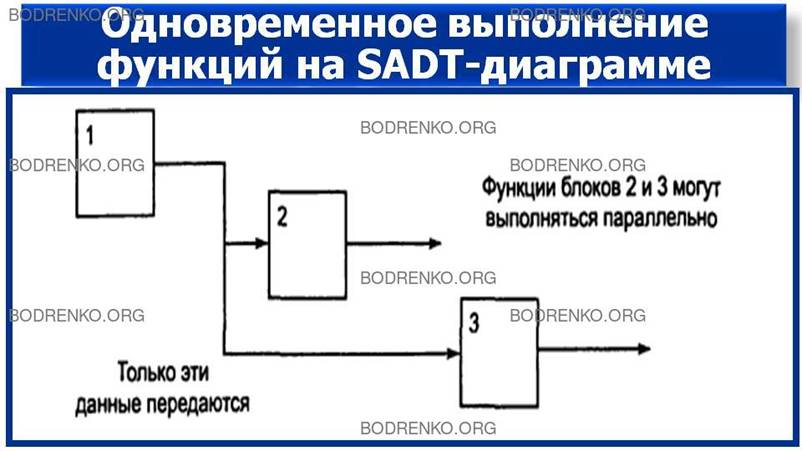
Рисунок 17. Одновременное выполнение.
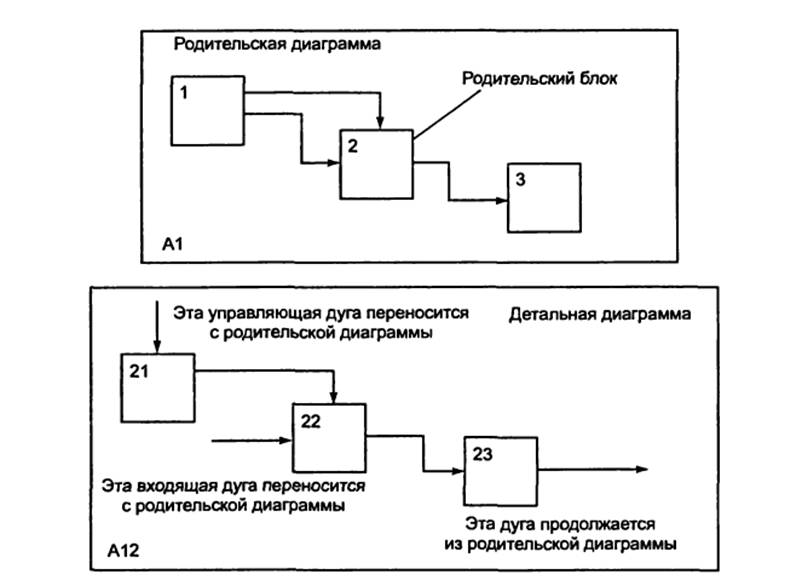
Рисунок 18. Соответствие родительской и
детальной диаграмм.
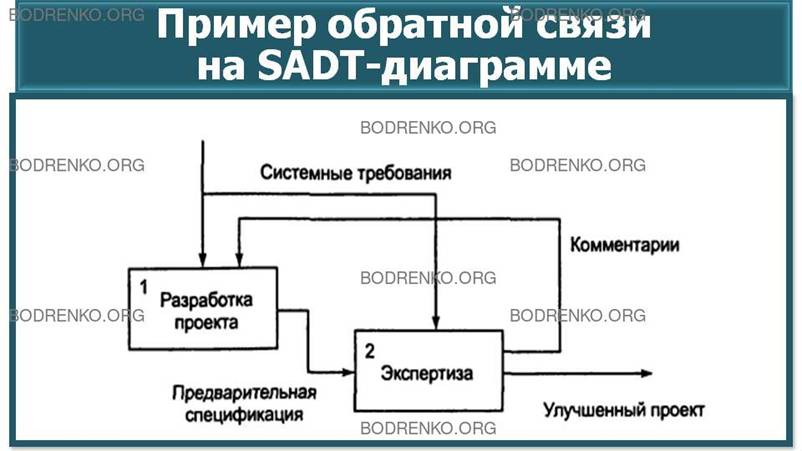
Рисунок 19. Пример обратной связи.
Последовательность
операций, время их выполнения не указываются
на SADT-диаграммах. Обратные связи, итерации, продолжающиеся процессы и перекрывающиеся (по
времени)
Функции
могут быть изображены с помощью дуг. Обратные связи могут выступать в виде комментариев,
замечаний, исправлений и т. д. (см. рисунок
19).
ПРИМЕР.
Разработку функциональных диаграмм продемонстрируем
на примере уточнения спецификаций программы сортировки одномерного массива с
использованием нескольких методов.
Диаграмма,
представленная на рисунке 20, является диаграммой
верхнего уровня. Она иллюстрирует исходные данные программы и ожидаемые
результаты.
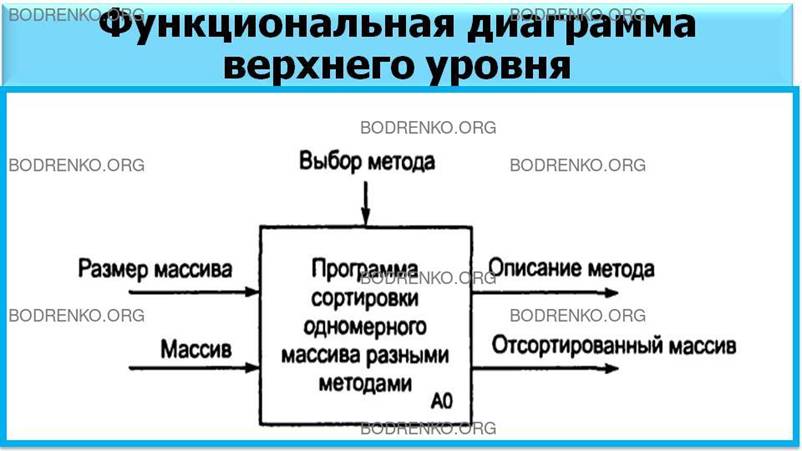
Рисунок
20. Функциональные диаграммы для программы сортировки массива: диаграмма
верхнего уровня.
Диаграмма,
представленная на рисунке 21, детализирует Функции программы. На ней показаны
три блока: Меню, Сортировка, Вывод
результата. Для каждого блока определены исходные данные, управляющие воздействия и
результаты. На детализирующей диаграмме
используются следующие обозначения:
I1 – размер массива;
I2 – массив;
С1
— выбор метода;
R1
— вывод описания метода;
R2
— отсортированный массив.
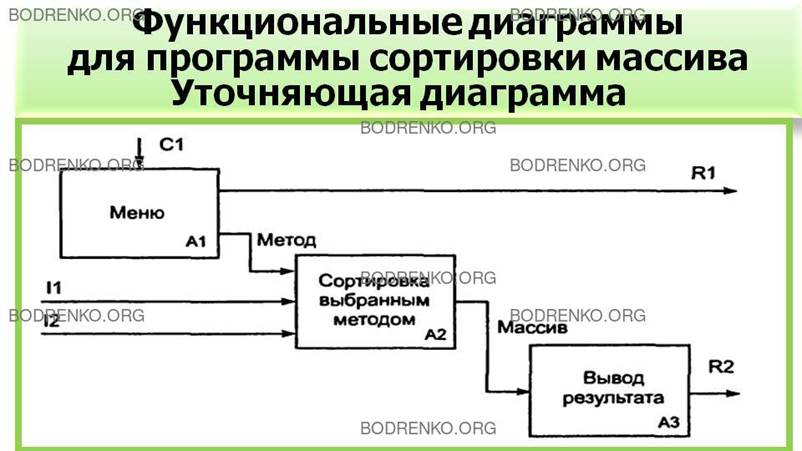
Рисунок
21. Функциональные диаграммы для программы сортировки массива: уточняющая
диаграмма.
3.
ДИАГРАММЫ ПОТОКОВ ДАННЫХ (DFD).
МОДЕЛЬ «СУЩНОСТЬ-СВЯЗЬ».
3.1. Диаграммы
потоков данных (DFD).
Такая
диаграмма состоит из трех типов узлов: узлов обработки данных, узлов хранения данных и
внешних узлов, представляющих внешние по
отношению к используемой диаграмме источники
или потребители данных.
Дуги
в диаграмме соответствуют потокам
данных, передаваемых от узла к узлу. Они помечены именами соответствующих
данных. Описание процесса, функции или
системы обработки данных, соответствующих узлу диаграммы, может быть представлено диаграммой
следующего уровня детализации, если
процесс достаточно сложен.
Для
изображения диаграмм потоков данных традиционно используют два вида нотаций:
нотации Йордана и Гейна — Сарсона (рисунок 22).

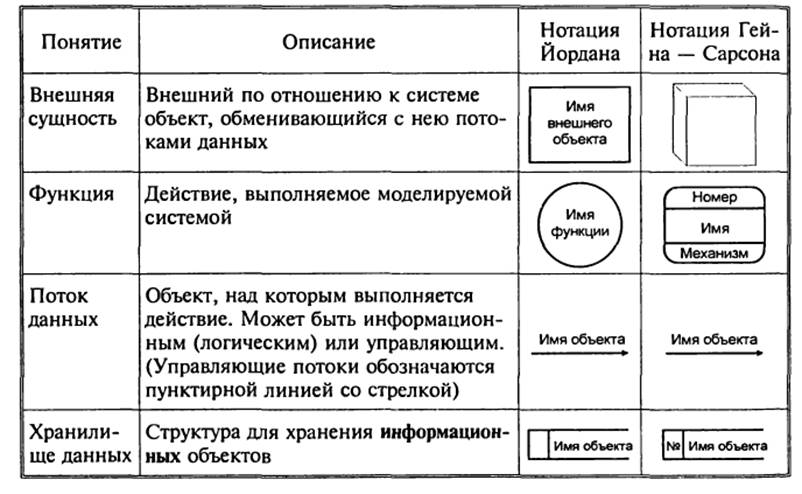
Рисунок 22. Обозначения элементов
диаграмм потоков данных.
Первым
шагом при построении иерархии диаграмм потоков данных является построение
контекстных диаграмм, показывающих, как
система будет взаимодействовать с пользователями и другими внешними системами.
При проектировании простых систем достаточно одной контекстной диаграммы,
имеющей звездную топологию, в центре которой располагается основной процесс,
соединенный с источниками и приемниками информации.
Для
сложных систем строится иерархия контекстных диаграмм, которая определяет взаимодействие
основных функциональных подсистем
проектируемой системы как между собой, так и с внешними входными и выходными
потоками данных и внешними объектами. При этом контекстная диаграмма верхнего уровня содержит набор подсистем,
соединенных потоками данных. Контекстные диаграммы следующего уровня детализируют содержимое и структуру подсистем.
После
построения контекстных диаграмм полученную модель следует проверить на полноту исходных
данных и отсутствие информационных
связей с другими объектами.
Для
каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее
детализация с помощью диаграмм потоков данных, при этом необходимо соблюдать
следующие правила:
-
правило
балансировки. Означает, что при детализации подсистемы можно использовать только те
компоненты (подсистемы, процессы,
внешние сущности, накопители данных), с
которыми она имеет информационную связь на родительской диаграмме;
-
правило
нумерации. Означает, что при детализации подсистем должна поддерживаться их
иерархическая нумерация. Например,
подсистемы, детализирующие подсистему с номером 2, получают номера 2.1, 2.2,
2.3 и т. д.
При
построении иерархии диаграмм потоков данных переходить к детализации процессов следует
только после определения структур данных, которые описывают содержание всех
потоков и накопителей данных. Структуры данных могут содержать альтернативы, условные вхождения и итерации.
Условное вхождение означает, что
соответствующие компоненты могут отсутствовать
в структуре. Альтернатива означает, что в структуру может входить один из перечисленных элементов.
Итерация означает, что компонент может повторяться в структуре некоторое указанное число раз. Для каждого
элемента данных может Указываться его тип (непрерывный или дискретный). Для непрерывных данных может указываться единица
измерения (кг, см и т. п.), диапазон значений, точность представления и форма Физического
кодирования. Для дискретных данных может указываться таблица допустимых значений.
Построенную
модель системы необходимо проверить на полноту и согласованность. В полной
модели все ее объекты (подсистемы, процессы, потоки данных) должны быть
подробно описаны и детализированы.
Выявленные недетализированные объекты
следует детализировать, вернувшись на предыдущие шаги разработки. В
согласованной модели для всех потоков данных и накопителей данных должно
выполняться правило сохранения информации: все поступающие куда-либо данные
должны быть считаны, а все считываемые данные должны быть записаны.
В
соответствии с вышесказанным процесс построения модели разбивается на следующие этапы:
1.
Выделение множества требований в основные функциональные группы — процессы.
2.
Выявление внешних объектов, связанных с разрабатываемой
системой.
3.
Идентификация основных потоков информации, циркулирующей между системой и внешними
объектами.
4.
Предварительная разработка контекстной диаграммы.
5.
Проверка предварительной контекстной диаграммы и внесение в нее изменений.
6.
Построение контекстной диаграммы путем объединения всех процессов
предварительной диаграммы в один процесс, а также группирования потоков.
7.
Проверка основных требований контекстной диаграммы.
8.
Декомпозиция каждого процесса текущей DFD с помощью детализирующей диаграммы или
спецификации процесса.
9.
Проверка основных требований по DFD соответствующего уровня.
10.
Добавление определений новых потоков в словарь данных при каждом их появлении на диаграммах.
11.
Проверка полноты и наглядности модели после построения каждых двух-трех уровней.
ПРИМЕР
2. Разработаем иерархию диаграмм потоков данных программы сортировки одномерных
массивов.
Для
начала построим контекстную диаграмму, для чего определим внешние сущности и потоки данных
между программой и внешними сущностями.
Внешней сущностью по отношению к
программе является Пользователь. Он выбирает метод сортировки и вводит исходные
данные, а затем получает от программы описание выбранного метода и
отсортированный массив. На рисунке 23 представлена контекстная диаграмма данной программы.
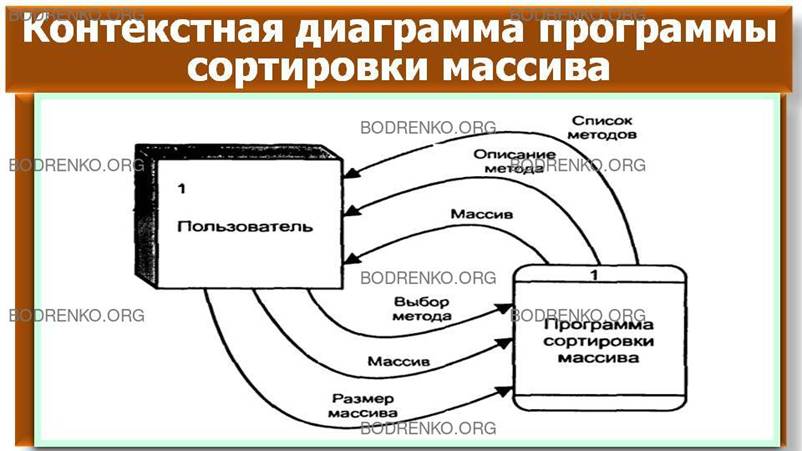
Рисунок 23. Контекстная диаграмма
программы сортировки массива.
После
детализации получилось три процесса: Меню, Сортировка, Вывод результата. Для хранения
описаний алгоритмов служит Хранилище
алгоритмов. Теперь определим потоки данных. Детализирующая диаграмма потоков
данных изображена на рисунке 24. Как мы видим, она несколько отличается от функциональной диаграммы (см. рисунок 21),
например, на ней показано хранилище данных для хранения описаний алгоритмов.
Это отличие является важным при
проектировании баз данных.
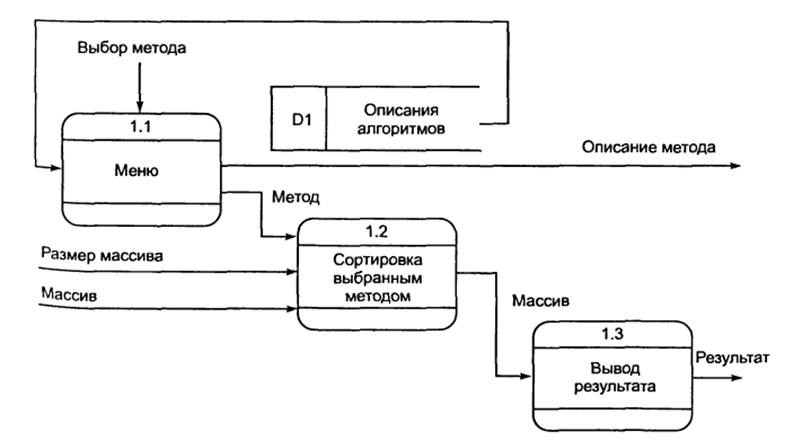
Рисунок
24. Детализирующая диаграмма потоков данных программы сортировки одномерного
массива (нотация Гейна — Сарсона).
3.2.
Диаграммы сущность—связь.
Базовыми
понятиями ER-модели данных (ER — Entity-Relationship) являются сущность,
атрибут и связь.
Первый
вариант модели «сущность—связь» был предложен в 1976 г. Питером Пин-Шэн Ченом.
В дальнейшем многими авторами были
разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация
Баркера и др.). Кроме того, различные программные средства, реализующие одну и
ту же нотацию, могут отличаться своими возможностями. Все варианты диаграмм «сущность—связь» исходят из
одной идеи — рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение
сущностей предметной области, их свойств
(атрибутов) и взаимосвязей между сущностями.
Поскольку
нотация Баркера является наиболее распространенной,
в дальнейшем будем придерживаться именно ее.
Основные понятия
ER-диаграмм
Сущность
— это класс однотипных объектов, информация о которых должна быть учтена в
модели.
Сущность
имеет наименование, выраженное
существительным в единственном числе, и
обозначается в виде прямоугольника с наименованием (рисунок 25, а). Примерами
сущностей могут быть такие классы объектов, как «Студент», «Сотрудник»,
«Товар».
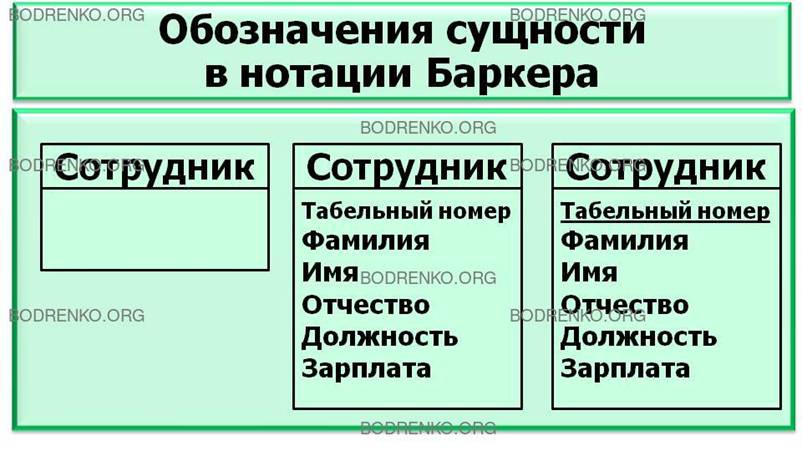
Рисунок
25. Обозначения сущности в нотации Баркера: а –
без атрибутов; б — с указанием атрибутов; в — с ключевым атрибутом.
Экземпляр
сущности — это конкретный представитель данной
сущности.
Например,
конкретный представитель сущности «Студент» — «Максимов». Причем сущности
должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности,
для того чтобы различать экземпляры.
Атрибут
сущности — это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование
атрибута должно быть выражено существительным в единственном числе (возможно, с
описательными оборотами или прилагательными).
Примерами
атрибутов сущности «Студент» могут быть такие атрибуты: «Номер зачетной книжки», «Фамилия»,
«Имя», «Пол», «Возраст», «Средний балл» и т. п.
Атрибуты
изображаются в прямоугольнике, обозначающем сущность (рисунок 25, б).
Ключ
сущности — это неизбыточный набор атрибутов, значения которых в совокупности являются
уникальными для каждого экземпляра
сущности.
При
удалении любого атрибута из ключа
нарушается его уникальность. Ключей у сущности может быть несколько. На
диаграмме ключевые атрибуты отображаются
подчеркиванием (рисунок 25, в).
Связь
— это отношение одной сущности к другой или к самой себе.
Имеется
возможность по одной сущности находить другие, связанные с ней. Например, связи между
сущностями могут выражаться следующими
фразами — «СОТРУДНИК может иметь несколько ДЕТЕЙ», «СОТРУДНИК обязан числиться
точно в одном ОТДЕЛЕ». Графически связь изображается линией, соединяющей две сущности (рисунок 26).
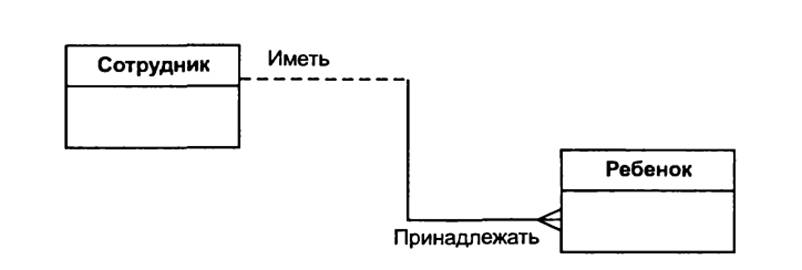
Рисунок 26. Пример связи между
сущностями.
Каждая
связь имеет одно или два наименования.
Наименование обычно выражается неопределенной
формой глагола: «Продавать», «Быть
проданным» и т. п. Каждое из наименований относится к своему концу связи. Иногда
наименования не пишутся ввиду их
очевидности.
Связь
может иметь один из следующих типов — рисунок 27.
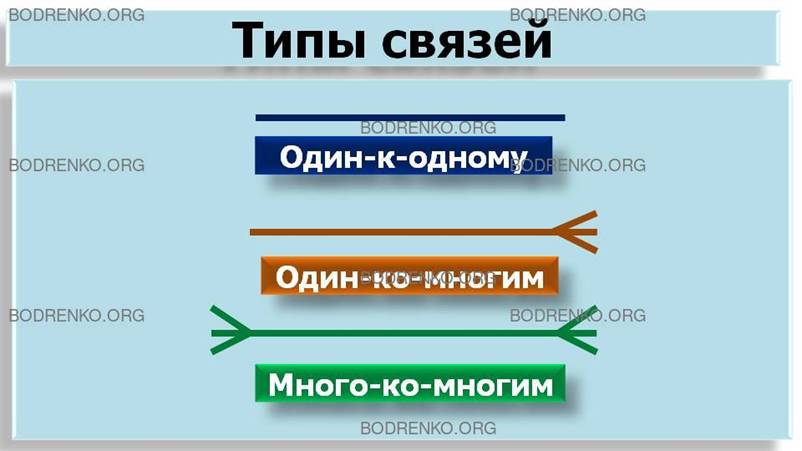
Рисунок 27. Типы связей.
Связь
типа один-к-одному
означает, что один экземпляр первой
сущности связан точно с одним экземпляром второй сущности. Такая связь чаще
всего свидетельствует о том, что мы неправильно
разделили одну сущность на две.
Связь
типа один-ко-многим
означает, что один экземпляр первой сущности связан с несколькими экземплярами
второй сущности. Это наиболее часто используемый тип связи. Пример такой связи
приведен на рисунке 26.
Связь
типа много-ко-многим
означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот. Тип
связи много-ко-многим является временным типом связи, допустимым на ранних
этапах разработки модели. В дальнейшем такую связь необходимо заменить двумя связями типа один-ко-многим
путем создания промежуточной сущности.
Каждая
связь может иметь одну из двух модальностей связи (рисунок 28).
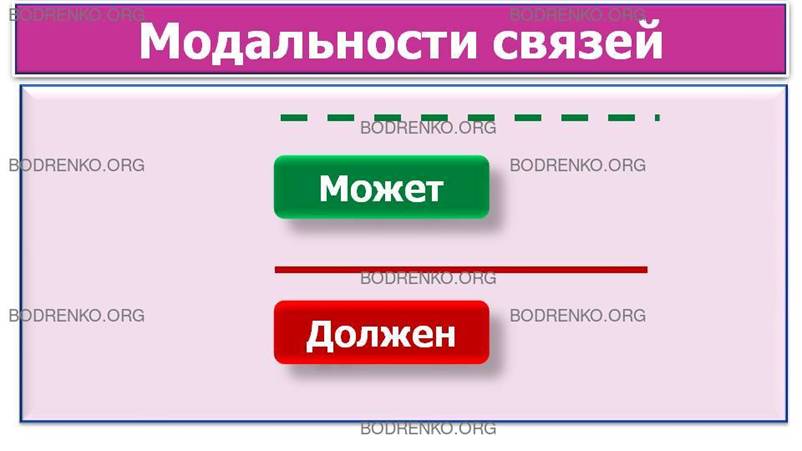
Рисунок 28. Модальности связей.
Связь
может иметь разную модальность с разных концов, как на рисунке 26. Каждая связь
может быть прочитана как слева направо, так и справа налево. Связь на рисунке
26 читается так: слева направо: «Сотрудник может иметь несколько детей»; справа
налево: «Ребенок должен принадлежать точно одному сотруднику».
3.3. Пример
разработки простой ER-диаграммы.
Необходимо
разработать информационную систему по заказу некоторой оптовой торговой фирмы,
которая должна выполнять следующие действия:
-
хранить информацию о покупателях;
-
печатать накладные на отпущенные товары;
-
следить за наличием товаров на складе.
Выделим
все существительные в этих предложениях — это будут потенциальные кандидаты на
сущности и атрибуты, и проанализируем их
(непонятные термины будем выделять знаком вопроса):
•
Покупатель — явный кандидат на
сущность.
•
Накладная — явный кандидат на
сущность.
•
Товар — явный кандидат на сущность
•
(?) Склад — а вообще, сколько
складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
•
(?) Наличие товара — это, скорее
всего, атрибут, но атрибут какой сущности?
Сразу
возникает очевидная связь между сущностями — «покупатели могут покупать много товаров» и
«товары могут продаваться многим
покупателям». Первый вариант диаграммы выглядит,
как показано на рисунке 29.
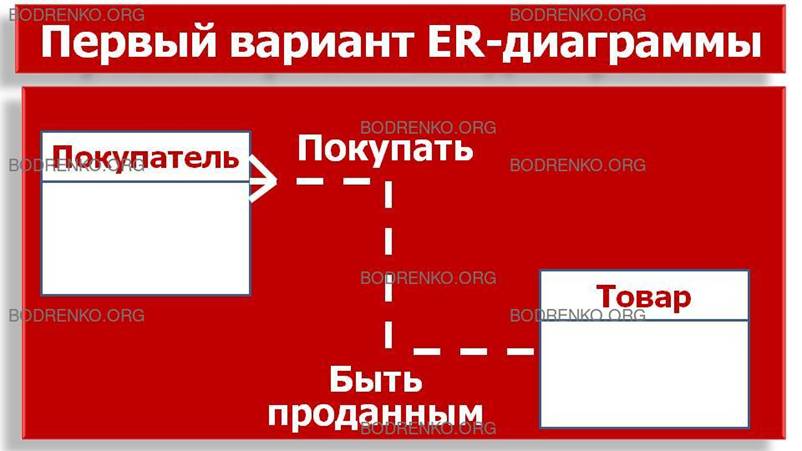
Рисунок 29. Первый вариант ER-диаграммы.
Задав
дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько
складов. Причем каждый товар может
храниться на нескольких складах и быть проданным с любого склада.
Куда
поместить сущности «Накладная» и «Склад» и с чем их связать? Спросим себя, как
связаны эти сущности между собой и с сущностями «Покупатель» и «Товар»?
Покупатели покупают товары, получая при этом накладные, в которые внесены
данные о количестве и цене купленного товара. Каждый покупатель может получить несколько накладных. Каждая
накладная обязана выписываться на одного покупателя. Каждая накладная обязана содержать
несколько товаров (не бывает пустых накладных).
Каждый
товар, в свою очередь, может быть продан нескольким покупателям по нескольким
накладным. Кроме того, каждая накладная
должна быть выписана с определенного склада, и с любого склада может быть выписано много
накладных. Таким образом, после уточнения диаграмма будет выглядеть следующим образом (рисунок 30).
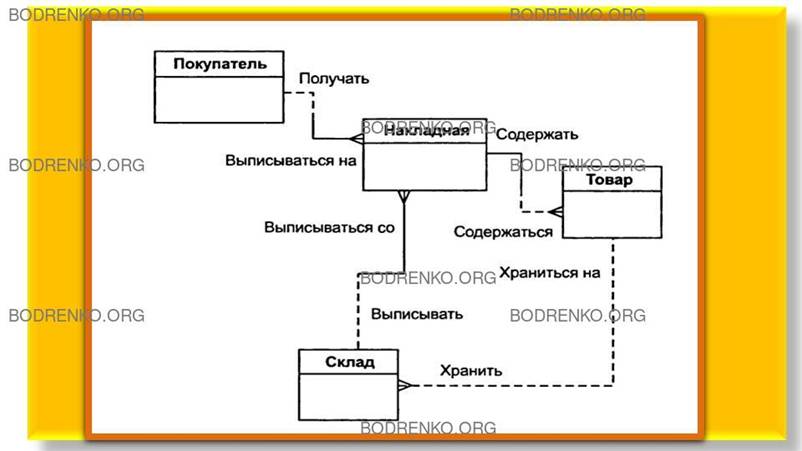
Рисунок 30. Промежуточный вариант
ER-диаграммы.
Пора
подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее:
•
каждый покупатель является юридическим лицом и имеет наименование, адрес,
банковские реквизиты;
•
каждый товар имеет наименование, цену, а также характеризуется единицами измерения;
•
каждая накладная имеет уникальный номер, дату выписки, список товаров с
количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного
покупателя;
•
каждый склад имеет свое наименование.
Снова
выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем
их:
-
Юридическое лицо — термин риторический,
мы не работаем с физическими лицами. Не обращаем внимания;
-
Наименование покупателя — явная
характеристика
-
Адрес — явная характеристика
покупателя;
•
Банковские реквизиты — явная
характеристика покупателя;
•
Наименование товара — явная характеристика
товара;
•
(?) Цена товара — похоже, что это
характеристика товара.
Отличается
ли эта характеристика от цены в накладной?
•
Единица измерения — явная
характеристика товара;
•
Номер накладной — явная уникальная
характеристика накладной;
•
Дата накладной — явная
характеристика накладной;
•
(?) Список товаров в накладной —
список не может быть атрибутом.
Вероятно, нужно выделить этот список в отдельную
сущность;
•
(?) Количество товара в накладной —
это явная характеристика, но характеристика
чего? Это характеристика не просто
«товара», а «товара в накладной»;
•
(?) Цена товара в накладной — опять
же это должна быть не просто характеристика товара, а характеристика товара в накладной.
Но цена товара уже встречалась выше — это одно и то же?
•
Сумма накладной — явная
характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров,
входящих в накладную;
•
Наименование склада — явная
характеристика склада.
В
ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось,
что каждый товар имеет некоторую текущую
цену. Это цена, по которой товар продается
в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же
товара в разных накладных, выписанных в разное время, может быть различной.
Таким
образом, имеется две цены — цена товара в накладной и текущая цена товара.
С
возникающим понятием «Список товаров в накладной» все довольно ясно. Сущности
«Накладная» и «Товар» связаны друг с другом отношением типа много-ко-многим.
Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим.
Для
этого требуется дополнительная сущность.
Этой
сущностью и будет сущность «Список товаров в накладной».
Связь
ее с сущностями «Накладная» и «Товар» характеризуется
следующими фразами: «каждая накладная
обязана иметь несколько записей из списка товаров в накладной», «каждая запись
из списка товаров в накладной обязана включаться ровно в одну накладную»,
«каждый товар может включаться в несколько записей из списка товаров в
накладной», «каждая запись из списка
товаров в накладной обязана быть связана ровно с одним товаром».
Атрибуты
«Количество товара в накладной» и «Цена товара в накладной» являются атрибутами
сущности «Список товаров в накладной».
Точно
так же поступим со связью, соединяющей сущности «Склад» и «Товар». Введем
дополнительную сущность «Товар на складе». Атрибутом этой сущности будет
«Количество товара на складе». Таким образом, товар будет числиться на любом
складе и количество его на каждом складе будет свое.
Теперь
можно внести все это в диаграмму (рисунок 31).
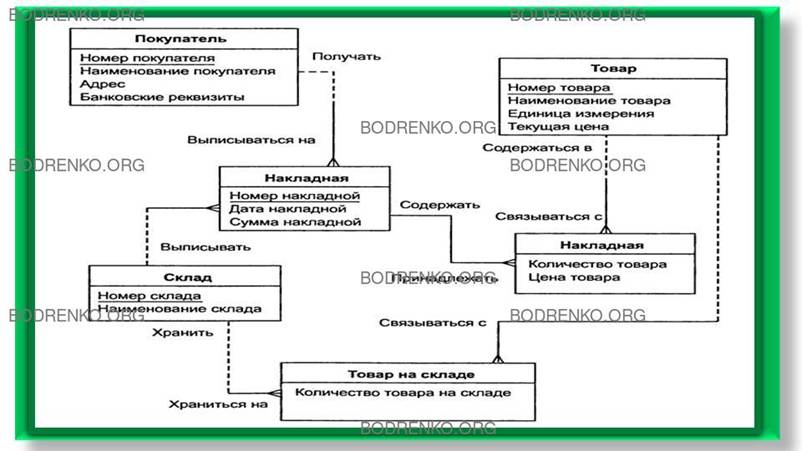
Рисунок 31. Окончательный вариант
ER-диаграммы.
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ.
[1] Благодатских В.А., Волнин В.А.,
Поскакалов К.Ф. Стандартизация разработки программных средств. Учебное пособие
/Под ред. О.С. Разумова. М.: Финансы и статистика, 2005. – 288 с., ил.
[2] Брауде Э. Технология разработки
программного обеспечения. СПб.: Питер, 2004. – 655 с.: ил.

[3] Вигерс К. Разработка требований к
программному обеспечению /Пер. с англ. – М.: ИТД «Русская Редакция», 2004. –
576.: ил.
[4] Гагарина Л.Г., Кокорева Е.В.,
Виснадул Б.Д. Технология разработки программного обеспечения. Учебное пособие /Под ред. Л.Г. Гагариной. –
М.: ИД «Форум»: ИНФРА-М, 2008. – 400 с.: ил. – (Высшее образование).
[5] Котов С.Л., Палюх Б.В., Федченко
С.Л. Разработка, стандартизация и сертификация программных средств и
информационных технологий и систем. Учебное пособие. Тверь.: ТГТУ, 2006. – 104
с.
