Математическое моделирование социально-экономических процессов. Модели прогнозирования социально-экономических процессов. Методы прогнозирования социально-экономических процессов. Прогнозирование экономической динамики на основе трендовых моделей. Трендовые модели, содержащие сезонную компоненту. Идентификация
Решение задач и выполнение научно-исследовательских разработок: Отправьте запрос сейчас: irina@bodrenko.org
математика, IT, информатика, программирование, статистика, биостатистика, экономика, психология
Пришлите по e-mail: irina@bodrenko.org описание вашего задания, срок выполнения, стоимость
Основы
математического моделирования
социально-экономических
процессов
Лекция 2
Тема лекции: «Модели прогнозирования социально-экономических процессов»

1. Методы прогнозирования социально-экономических процессов.
2. Прогнозирование экономической динамики на основе трендовых моделей.
3. Трендовые модели, содержащие сезонную компоненту.

1. МЕТОДЫ ПРОГНОЗИРОВАНИЯ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ПРОЦЕССОВ.
1.1. Построение моделей прогнозирования.
В самом широком смысле
ПРОГНОЗИРОВАНИЕ (в переводе с греческого πρόγνωσις – знание наперед, предсказание, предвидение) – определение тенденций и перспектив развития тех или иных процессов на основе анализа данных об их прошлом и нынешнем состоянии.
Процедуры построения прогнозов используются практически во всех областях знания, в том числе в экономике, социологии, технике, образовании и т. д. Прогнозирование по своему характеру неразрывно связано со временем — посредством прогноза мы как бы пытаемся разглядеть будущее в настоящем. Способы такого «заглядывания в будущее» весьма разнообразны — от внутреннего голоса и исторических аналогий до экспертных оценок и сложных эконометрических моделей. Поэтому необходимость прогноза развития той или иной ситуации, будущих изменений тех или иных обстоятельств, ставит нас перед непростой проблемой выбора вполне конкретного метода прогнозирования. Этот выбор зависит от множества факторов. Отметим некоторые из них: наличие данных (количественное выражение накопленного в прошлом опыта), планируемый момент исполнения и желаемая точность прогноза, а также временные и стоимостные затраты на его составление.
По тому, на какой момент или период времени он составляется, прогноз может быть:
- краткосрочным – до года, но обычно на квартал;
- среднесрочным – от года до трех лет;
- долгосрочным – на три года и больше.
Интуитивно ясно, что чем меньше промежуток времени, отделяющий настоящий момент от прогнозируемого, тем большим будет объем хорошо предсказываемых событий — для того, что может произойти завтра, прогноз значительно проще и достовернее, нежели для того, что произойдет через год или через пять лет. Хотя, конечно, реальное развитие событий может оказаться и весьма далеким от прогнозируемого.
Итеративная процедура построения МАТЕМАТИЧЕСКОЙ МОДЕЛИ ПРОГНОЗИРОВАНИЯ, основана на идентификации, оценивании и диагностической проверке.
Под идентификацией подразумевается использование любой информации о том, как были получены рассматриваемые числовые значения (как был генерирован ряд), с целью отыскания набора экономичных моделей, заслуживающих опробования. Экономичные модели должны обладать максимальной простотой и минимальным числом параметров, но при этом адекватно описывать наблюдения. Методы идентификации определяют класс пробных моделей, для которых применяются более формальные и эффективные методы оценивания.
Под оцениванием подразумевается процедура получения оценок параметров моделей, определяющих адекватность моделей, ибо неадекватность выбранной модели может быть вызвана неэффективностью процедуры оценки параметров модели, а не тем, что неадекватен вид модели.
Под диагностической проверкой подразумевается проверка согласования подогнанной модели с исходными данными, чтобы вскрыть недостатки модели и улучшить ее. В частности, метод диагностической проверки модели может базироваться на введении избыточного числа параметров, т. е. в оценивании параметров для несколько более общей модели, чем ожидаемая модель. Этот подход исходит из того, что мы можем угадать неадекватные свойства модели, и требует исследования остаточных ошибок после подгонки модели. Он позволяет определить, какие необходимы изменения модели.
ИТЕРАЦИОННЫЙ ПОДХОД К ПОСТРОЕНИЮ МАТЕМАТИЧЕСКИХ МОДЕЛЕЙ ВКЛЮЧАЕТ В СЕБЯ СЛЕДУЮЩИЕ ЭТАПЫ.
Этап 1. На основе теории и практики явления выбирается класс моделей, ориентируясь на те цели, для которых создается модель.
Этап 2. Разрабатываются простейшие методы идентификации подклассов этих моделей. Процесс идентификации может быть использован для получения грубых предварительных оценок параметров моделей.
Этап 3. Пробная модель подгоняется к экспериментальным данным; оцениваются ее параметры. Грубые оценки, полученные на этапе идентификации, теперь можно использовать как начальные значения в более точных итеративных методах оценивания параметров.
Этап 4. Диагностические проверки позволяют выявить возможные дефекты подгонки и диагностировать их причины. Если такие дефекты не выявлены, модель готова к использованию. Если обнаружено какое-либо несоответствие, итеративные циклы идентификации, оценок и диагностической проверки повторяются до тех пор, пока не будет найдено подходящее представление модели.
В практике широко применяются параметрические модели, что повысило интерес к задачам оценивания параметров и к родственным вопросам при построении таких моделей по экспериментальным данным.
На практике отыскание подходящей математической модели прогнозирования какого-либо социально-экономического процесса может быть достаточно трудной задачей. При построении модели надо стремиться ответить на следующие вопросы:
1) как оценить качество модели;
2) как учесть всю имеющуюся информацию;
3) в чем состоит оптимальная стратегия получения недостающей информации;
4) как поступить с нелинейностями;
5) можно ли аппроксимировать сложную систему простой моделью.
Ответы на эти вопросы зависят от конкретного класса экономико-математических систем.
1.2. Методы составления прогнозов.
Многие методы прогнозирования требуют наличия значительного количества начальных данных и при их отсутствии просто не работают. Другие, напротив, разрабатываются при условии отсутствия достоверной количественной информации. Тем самым существующие методы составления прогнозов можно условно разбить на две группы — количественные и качественные.

Качественные, или экспертные, методы прогнозирования (qualitative methods) строятся на использовании мнений специалистов в соответствующих областях (экспертов).
Количественные методы прогнозирования (quantitative methods) основываются на обработке числовых массивов данных (как значительных по объему, так и сравнительно небольших) и в свою очередь разделяются на каузальные, или причинно-следственные, методы (causal methods) и методы анализа временных рядов (time series methods).
Основанный на допущении, в соответствии с которым происшедшее в прошлом дает хорошее приближение в оценке будущего, анализ временных рядов является способом выявления тенденций прошлого и продления их в будущее.
Для составления среднесрочных и долгосрочных прогнозов применяются каузальные и качественные методы прогнозирования, которые значительно сложнее методов анализа временных рядов.
Каузальные методы применяются в тех случаях, когда искомое состояние зависит не только от времени, но и от нескольких, и даже многих переменных. Отыскание математических связей (уравнений и/или неравенств) между всеми этими переменными и составляет суть каузального метода прогнозирования.
Далее мы остановимся на описании особенностей каждого из перечисленных выше типов прогнозирования более подробно, а также расскажем о некоторых конкретных методах составления прогнозов.
1.3. Количественные методы прогнозирования.
В задачах прогнозирования временные ряды используются при наличии значительного количества реальных значений рассматриваемого показателя из прошлого и при условии, что наметившаяся в прошлом тенденция ясна и относительно стабильна. При этом неявно предполагается, что прошлое является хорошим проводником в будущее. Анализ временных рядов позволяет предопределить, что должно произойти при отсутствии вмешательства извне, и, значит, не может предсказать изменения тенденции. Тем самым, подобным анализом предпочтительнее пользоваться при составлении краткосрочных прогнозов. Важнейшей задачей анализа временных рядов является выявление основной тенденции поведения системы, как результата влияния комплекса причин, действующих на изучаемый процесс.
Можно выделить два вида прогнозируемых характеристик системы, зависящих от времени: переменные состояния и переменные интенсивности.
Переменная состояния определяется периодически, и ее значение в течение небольшого интервала времени не зависит от времени, прошедшего с момента начала наблюдения.
Переменная интенсивности также определяется периодически, но ее значение пропорционально времени, прошедшему с момента предыдущего наблюдения. Если переменная состояния характеризует количество, то переменная интенсивности — скорость его изменения. Величина промежутков времени между измерениями входных переменных системы с целью проверки и уточнения ранее сделанных прогнозов о выводных переменных зависит главным образом от длительности времени упреждения и наибольшей частоты циклических изменений в системе, которые должна отражать модель.
Математическую модель системы называют детерминированной, если входящие в нее описания воздействия и параметры модели являются постоянными или детерминированными функциями переменных состояния и времени.
Математическую модель системы называют статистической (стохастической), если функции, описывающие воздействия и параметры модели, являются случайными функциями или случайными величинами. Для стохастических (вероятностных) динамических систем текущее состояние в момент t1, то есть значение показателя x1 = x(t1) и входное воздействие ω = ω(t1,t2) определяют в момент t2 не x2 = Х(t2), а лишь его вероятностное распределение.
Модели временных рядов и исследуемых процессов, необходимые для получения оптимального прогнозирования, в действительности являются стохастическими, поскольку на изучаемый процесс действует большое число неизвестных факторов и нельзя предложить детерминированную модель, допускающую точное вычисление будущего поведения объекта. Можно вычислить вероятность того, что некоторое будущее значение будет принадлежать определенному интервалу. В дальнейшем будем различать вероятностную модель или стохастический процесс и наблюдаемый временной (вариационный) ряд: x1, x2,..., xn, который рассматривается как выборочная реализация.
Исходные данные обычно представляют собой результаты выборочных наблюдений либо переменной интенсивности, либо переменной состояния. Результаты наблюдений регистрируются с ошибками, которые возникают как при наблюдениях, так и при регистрации данных. Кроме того, изучаемый процесс может иметь стохастическую природу. Результаты наблюдений могут содержать и аномальные эффекты. Поэтому не каждую совокупность зарегистрированных по мере поступления реальных данных следует считать подходящим рядом, на основании которого можно составлять прогноз. Перед тем как подобрать коэффициенты модели по исходным данным, из последних должны быть исключены выбросы, т. е. результаты наблюдений, которые не характеризуют прогнозируемый процесс.
Ни в одном из статистических методов прогнозирования не может быть заранее предусмотрено изменение модели прогнозируемого процесса. Во многих случаях изменения в изучаемом процессе можно предвидеть заранее, но в модель прогноза они не менее не включаются, так как последствия таких изменений не могут быть точно рассчитаны. Тем не менее, на основе тщательного анализа различных вариантов можно предсказать характер изменений. В любой отдельный период времени существует, очевидно, несколько серий прогнозов, отличных от простого описательного прогноза. Это позволяет минимизировать время, затрачиваемое на внесение изменений. Модель прогноза может все более усложняться, когда это экономически оправдано и позволяет глубже проникнуть в механизм наблюдаемых явлений.
При представлении совокупности результатов наблюдений в виде временных рядов фактически используется предположение о том, что наблюдаемые величины принадлежат некоторому распределению, параметры которого и их изменение можно оценить. По этим параметрам (как правило, по среднему значению и дисперсии, хотя иногда используется и более полное описание) можно построить одну из моделей вероятностного представления процесса. Другим вероятностным представлением является модель в виде частотного распределения с параметрами pj для относительной частоты наблюдений, попадающих в j-й интервал. При этом если в течение принятого времени упреждения не ожидается изменения распределения, то решение принимается на основании имеющегося эмпирического частотного распределения.
При проведении прогнозирования необходимо иметь в виду, что все факторы, влияющие на поведение системы в базовом (исследуемом) и прогнозируемом периодах, должны быть неизменны или изменяться по известному закону. Первый случай реализуется в однофакторном прогнозировании, второй — при многофакторном.
Многофакторные динамические модели должны учитывать пространственные и временные изменения факторов (аргументов), а также (при необходимости) запаздывание влияния этих факторов на зависимую переменную (функцию). Многофакторное прогнозирование позволяет учитывать развитие взаимосвязанных процессов и явлений. Основой его является системный подход к изучению исследуемого явления, а так же процесс осмысливания явления, как в прошлом, так и в будущем.
В многофакторном прогнозировании одной из основных проблем является проблема выбора факторов, обуславливающих поведение системы, которая не может быть решена чисто статистическим путем, а только при помощи глубокого изучения существа явления. Здесь следует подчеркнуть примат анализа (осмысливания) перед чисто статистическими (математическими) методами изучения явления. В традиционных методах (например, в методе наименьших квадратов) считается, что наблюдения независимы друг от друга (по одному и тому же аргументу). В действительности существует автокорреляция и ее неучет приводит к неоптимальности статистических оценок, затрудняет построение доверительных интервалов для коэффициентов регрессии, а также проверку их значимости. Автокорреляция определяется по отклонениям от трендов. Она может иметь место, если не учтено влияние существенного фактора или нескольких менее существенных факторов, но направленных «в одну сторону», либо неверно выбрана модель, устанавливающая связь между факторами и функцией. Для выявления наличия автокорреляции применяется критерий Дурбина—Уотсона. Для исключения или уменьшения автокорреляции применяется переход к случайной компоненте (исключение тренда) или введение времени в уравнение множественной регрессии в качестве аргумента.
В многофакторных моделях возникает проблема и мультиколлинеарности — наличие сильной корреляции между факторами, которая может существовать вне всякой зависимости между функцией и факторами. Выявив, какие факторы являются мультиколлинеарными, можно определить характер взаимозависимости между мультиколлинеарными элементами множества независимых переменных.
В многофакторном анализе необходимо наряду с оценкой параметров сглаживающей (исследуемой) функции построить прогноз каждого фактора (по неким другим функциям или моделям). Естественно, что значения факторов, полученные в эксперименте в базисном периоде, не совпадают с аналогичными значениями, найденными по прогнозирующим моделям для факторов. Это различие должно быть объяснено либо случайными отклонениями, величина которых выявлена указанными различиями и должна быть учтена сразу же при оценке параметров сглаживающей функции, либо это различие не случайно и никакого прогноза делать нельзя. То есть в задаче многофакторного прогнозирования исходные значения факторов, как и значения сглаживающей функции, должны быть взяты с соответствующими ошибками, закон распределения которых должен быть определен при соответствующем анализе, предшествующем процедуре прогнозирования.
1.4. Каузальные методы прогнозирования.
В случае значительных требований к точности прогноза и при наличии большого (даже огромного) массива данных используются каузальные, или причинно-следственные, модели прогнозов, в которых прогнозируемая величина является функцией большого числа переменных. Объемы продаж товара могут зависеть от цены продукта, затрат на рекламу, действий конкурентов, уровня доходов и других независимых переменных. Если связи между этими переменными удается описать математически корректно, то точность каузального прогноза может оказаться довольно высокой. Но как правило, это требует больших объемов данных и существенно больших интеллектуальных, временных и финансовых затрат, чем анализ временных рядов. К тому же расчет каузальных моделей связан с большими объемами вычислений, что возможно лишь при наличии мощной вычислительной техники. Мы ограничимся краткой характеристикой трех каузальных методов прогнозирования
1) Многомерные регрессионные методы (модели) (multiple regression models), посредством которых регрессионная зависимость между величинами устанавливается по статистическим данным, являются наиболее распространенными количественными методами прогнозирования. Простейшее представление о регрессионных моделях дает описанный выше метод проецирования тренда, в котором регрессионная зависимость устанавливается между прогнозируемым показателем и одной переменной — временем. Многомерные модели линейной регрессии можно рассматривать как естественное обобщение этого метода.
1)
2) Эконометрические методы (модели) (econometric models) дают количественное описание закономерностей и взаимосвязей между экономическими объектами и процессами и разрабатываются для прогнозирования динамики экономики. Типичная эконометрическая модель представляет собой систему из тысяч уравнений, решение которой требует мощных вычислительных средств.
2)
3) Компьютерная имитация (computer simulation). С появлением современных вычислительных средств уровень сложности математических моделей, при помощи которых можно делать правильные предсказания о динамике процессов, существенно вырос. Появились модели, способные создавать «иллюзию реальности». Называемые имитационными, эти модели являются как бы промежуточным звеном между реальностью и обычными математическими моделями.
3)

Имитационные модели находятся как бы на пределе возможностей вычислительной техники (и системного программирования).
ЗАМЕЧАНИЕ. Всегда существуют процессы настолько сложные, что они не поддаются изучению математическими методами. Это не означает, однако, что они непознаваемы. Просто их рассматривают гуманитарными методами и средствами искусства — столь же необходимыми методами изучения реальности, как и математические методы. А подвижная граница между гуманитарными и математическими методами изучения (в том числе и прогнозирования) реальности проходит как раз по имитационными моделям в том понимании этого термина, о котором идет речь здесь.
1.5. Качественные методы
прогнозирования.
Следует иметь в виду, что
описанные выше методы — это далеко не весь, а иногда и не лучший инструментарий
для составления прогнозов. Существует множество других, более изощренных
статистических методов. Помимо количественных, существуют также качественные
методы, которые используются в условиях недостаточного количества или
отсутствия фактических данных.
При отсутствии количественных данных, или когда количественная модель получается слишком дорогой, используются качественные методы прогнозирования, которые строятся на основе разного рода экспертных оценок. Опишем некоторые из этих методов.
1) Дельфийский метод (Delphi method), или метод экспертных оценок, представляет собой процедуру, позволяющую приходить к согласию группе экспертов из самых разных, но взаимосвязанных областей. Работа над составлением прогноза этим методом организуется так: каждому эксперту независимо рассылается вопросник по поводу рассматриваемой проблемы, ответы экспертов и их мнения кладутся в основу подготовки следующего вопросника, вновь рассылаемого экспертам, и так далее до тех пор, пока эксперты не приходят к согласию (при условии запрета на открытые дискуссии между экспертами). Обычно эта рассылка повторяется 3-4 раза.
1)
2) Изучение рынка (market research), или модель ожидания потребителя. Прогноз строится на основании разнообразных опросов потребителей и последующей статистической обработки.
2)
3) Метод консенсуса (panel consensus), или мнение жюри, заключается в соединении и усреднении мнений группы экспертов в процессе «мозгового штурма».
3)
4) Совокупное мнение сбытовиков (grass-roots forecasting). Метод опирается на мнение непосредственно контактирующих с потребителем торговых агентов.
4)
5) Историческая аналогия (historical analogy) обычно используется в тех случаях, когда нужно дать прогноз продажи товара, по своим характеристикам близкого к выпущенному ранее (например, его модификации).
5)

Сравнительные характеристики этих пяти методов приведены на следующих рисунках.
На рисунке 1 указано среднее время (в месяцах), требуемое для составления прогноза.
![]()


![]() 3 -
3 -

![]() -
-
![]() 2 -
2 -
![]() -
-
1 -
![]()
d m p q h
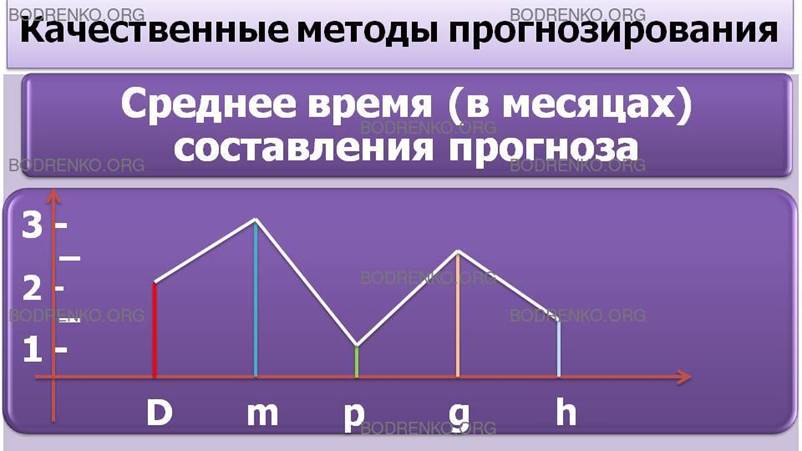
Рис. 1. Среднее время (в месяцах) составления прогноза.
d — «Delphi method», m — «market research», p —
«panel consensus», g — «grass-roots forecasting», h — «historical analogy»;
На рисунке 2 приведена средняя цена (в тыс. долл.) составления прогноза.
![]()


![]() 10 -
10 -
-
8 -
-
6 -
-
4 -
![]() -
-
2 -
![]()
d m p q h
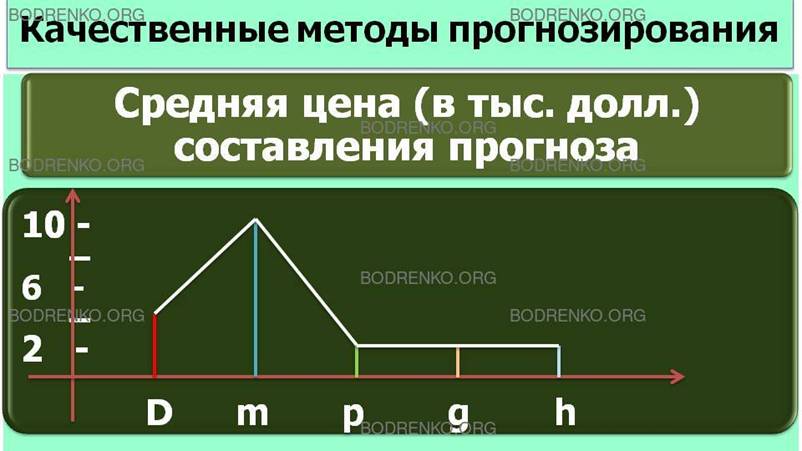
Рис. 2. Средняя цена (в тыс. долл.) составления прогноза.
2. ПРОГНОЗИРОВАНИЕ ЭКОНОМИЧЕСКОЙ ДИНАМИКИ НА ОСНОВЕ ТРЕНДОВЫХ МОДЕЛЕЙ.
При составлении как краткосрочных, так и долгосрочных планов руководители, менеджеры вынуждены прогнозировать будущие значения таких важнейших показателей, как, например, объем продаж, ставки процента, издержки и т.д. Мы рассмотрим возможности применения в целях прогнозирования фактических данных за прошлые промежутки времени.
При характеристике регрессионных методов колебания зависимой переменной объясняются на основе изучения соответствующих значений независимой переменной. Здесь мы будем использовать аналогичный подход, причем в качестве независимой будет выступать переменная времени. К примеру, мы хотим объяснить колебания объемов продаж только через изменение значений этого показателя во времени, без учета каких-либо других факторов. Если удается выявить определенную тенденцию изменения фактических значений, то ее можно использовать для прогнозирования будущих значений данного показателя. Множество данных, в которых время является независимой переменной, называется временным рядом. Модель, построенную по ретроспективным данным, не всегда можно использовать в прогнозировании отдельных показателей. Например, план некоторой компании может коренным образом измениться, если эта компания несет убытки. Кроме того, существует множество внешних факторов, которые могут полностью изменить тенденцию, существовавшую ранее. К таким факторам можно отнести существенные изменения цен на сырье, резкое увеличение уровня инфляции в мире в целом или стихийные бедствия, которые непредсказуемым образом могут повлиять на предпринимательскую деятельность.
Прогнозирование экономических показателей на основе трендовых моделей, как и большинство других методов экономического прогнозирования, основано на идее экстраполяции как метода научного прогнозирования.
Под ЭКСТРАПОЛЯЦИЕЙ (от экстра... и лат. polio – приглаживаю, изменяю) обычно понимают распространение закономерностей, связей и соотношений, действующих в изучаемом периоде, за его пределы.
В более широком смысле слова экстраполяцию рассматривают как получение представлений о будущем на основе информации, относящейся к прошлому и настоящему. В процессе построения прогнозных моделей в их структуру иногда закладываются элементы будущего предполагаемого состояния объекта или явления, но в целом эти модели отражают закономерности, наблюдаемые в прошлом и настоящем, поэтому достоверный прогноз возможен лишь относительно таких объектов и явлений, которые в значительной степени детерминируются прошлым и настоящим.
Существуют две основные формы детерминации: внутренняя и внешняя.
Внутренняя детерминация, или самодетерминация, более устойчива, ее проще идентифицировать с использованием экономико-математических моделей.
Внешняя детерминация определяется большим числом факторов, поэтому учесть их все практически невозможно.
Например, адаптивные методы моделирования отражают общее совокупное влияние на экономическую систему внешних факторов, т.е. отражают внешнюю детерминацию.
Методы, базирующиеся на использовании трендовых моделей социально-экономических процессов, представленных одномерными временными рядами, отражают внутреннюю детерминацию объектов и явлений.
2.1. Понятие временного ряда.
Временным (динамическим, или хронологическим) рядом называется последовательность значений некоторого показателя во времени (например, объемов продаж, значений индексов, процентных ставок, отношений курсов валют и т.д.).
Динамический ряд рассматривается как сумма детерминированной и случайной компонент.
Детерминированная компонента выражается некоторой аппроксимирующей функцией, отражающей закономерность развития исследуемого явления.
Появление случайной компоненты определяется сложным переплетением параметров системы, влиянием на их величину большого числа неизвестных факторов, действующих в разных направлениях, что находит свое выражение в отклонении значений показателей системы от основной тенденции развития. Дополнительный вклад вносит и аппроксимирующая модель, которая не в состоянии описать все особенности системы.
Для описания стохастических элементов временных рядов и их прогноза используются три различных понятия — помехи, остатки и ошибки.
Понятие помехи связано с собственной изменчивостью процесса и неопределенностью, вносимой при наблюдении за ним. Следовательно, помеха является составной частью используемых данных.
Под остатками понимается разность между результатами наблюдений и соответствующими значениями, вычисленными с помощью прогнозирующей их модели. Таким образом, остатки связаны с прошлыми данными и моделью, которая использовалась для их оценок.
Одним из существенных критериев, которым часто руководствуются при выборе того или иного метода прогнозирования, является полная стоимость прогноза, слагающаяся из затрат на его составление и цены ошибки прогноза. Поэтому стремление заказчика сделать эту стоимость как можно меньшей нужно воспринимать совершенно естественно.
Ошибки прогноза представляют собой разницу между прогнозом, сделанным
в настоящее время, и тем, что будет наблюдаться позднее в момент времени, для
которого составлен прогноз.
2.2. Понятие тренда временного ряда.
Тренд (от англ. trend — тенденция) — основная тенденция изменения временного ряда.
Тренд в экономике — направление преимущественного движения показателей. Обычно тренд рассматривается в рамках технического анализа, где подразумевают направленность движения цен или значений индексов.
В прогнозировании важно предварительно проанализировать характер изучаемого явления для определения вида его описания. Важно выяснить: процесс хорошо описывается основной тенденцией (трендом) или процесс зависит от изменения некоторого набора показателей, отражающих структуру процесса. Выбор вида описания предопределяет точность прогноза на будущее. Наиболее часто отклонения от основной тенденции развития (тренда) рассматриваются как стационарный случайный процесс, к которому применимы методы прогнозирования стационарных случайных процессов. Если случайная компонента не является стационарной, то производят определенные преобразования, чтобы сделать случайную компоненту хотя бы стационарной в определенных условиях.
При экстраполяционном прогнозировании экономической динамики на основе временных рядов с использованием трендовых моделей выполняются следующие основные этапы.
1. Предварительный анализ данных.
2. Формирование набора моделей (например, набора кривых роста), называемых, функциями-кандидатами.
3. Численное оценивание параметров моделей.
4. Определение адекватности моделей.
5. Оценка точности адекватных моделей.
6. Выбор лучшей модели.
7. Получение точечного и интервального прогнозов.
8. Верификация прогноза.
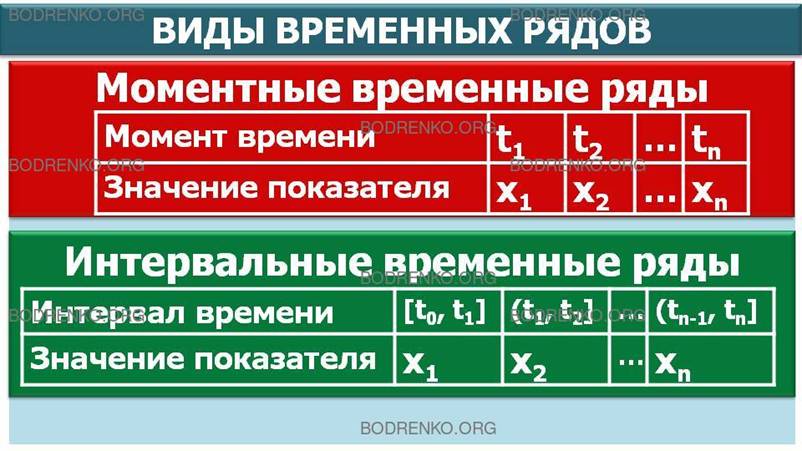
2.3. Виды временных рядов.
Различают два вида временных рядов.
Моментные временные ряды, когда значения рассматриваемого показателя x1, x2, , … xn,
отнесены к определенным моментам времени (например, дням) t1, t2, …, tn, при этом обычно считается, что t1 < t2 < … < tn,
Интервальные временные ряды, когда указаны соответствующие промежутки времени, интервалы: [t0, t1], (t1, t2], (t2, t3], … (tn-1, tn], где t0 < t1 < t2 < … < tn,
Временные ряды можно задавать при помощи таблиц (рис. 3, рис. 4).
|
Момент времени |
t1 |
t2 |
… |
tn |
|
Значение показателя |
x1 |
x2 |
… |
xn |
Рис. 3. Моментный ряд.
|
Интервал времени |
[t0, t1] |
(t1, t2] |
… |
(tn-1, tn] |
|
Значение показателя |
x1 |
x2 |
… |
xn |
Рис. 4. Интервальный ряд.
Временные ряды можно задавать графически (рис. 5, рис. 6).
![]() x
x
![]()
![]()
![]() xi
xi

t1 t2 ti … tn t
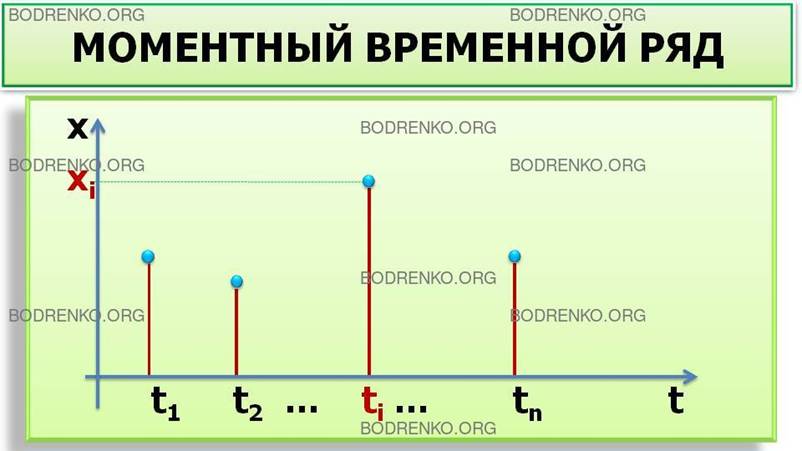
Рис. 5. Моментный ряд.
![]() x
x
![]()
![]()
![]()
![]()
![]()
![]()
![]() xi
xi
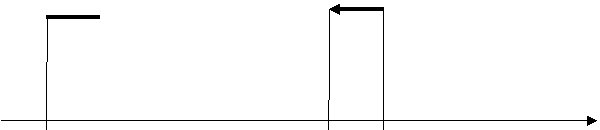
t0 t1 t2 ti-1 ti … tn-1 tn t
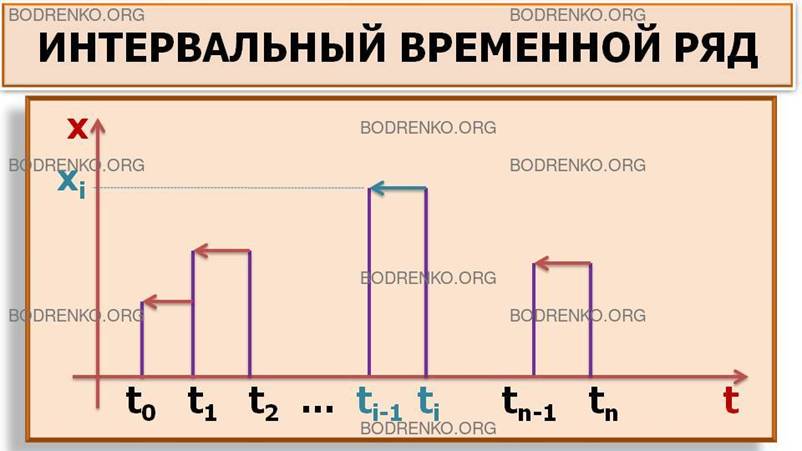
Рис. 6. Интервальный ряд.
Развитие процессов, реально наблюдаемых в жизни, складывается из некоторой устойчивой тенденции (тренда) и некоторой случайной составляющей, выражающейся в колебании значений показателя вокруг тренда. На рисунках 7, 8 показано, как могут зависеть объемы продаж одного и того же товара на двух стадиях его жизненного цикла (в начале и в конце продаж). Новым видам продукции соответствует возрастающий тренд, тогда как устаревшим продуктам на заключительной стадии их жизненного цикла — убывающий
Объем продаж
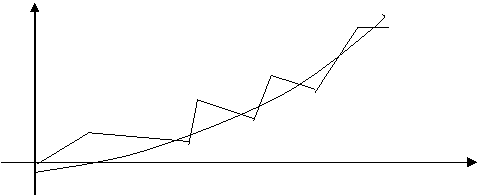
Время t
Рис. 7. Начало жизненного цикла.
Объем продаж
![]()
![]()
Время t
Рис. 8. Конец жизненного цикла.
Временные ряды содержат такие
элементы, как собственно тренд, сезонная вариация и циклическая вариация.
Основная тенденция характеризуется трендом. Для выявления основной тенденции (тренда) применяют сглаживание рядов динамики. Кривые тренда сглаживают динамический ряд значений показателя, выделяя общую тенденцию. Именно выбор кривой тренда, сам по себе являющийся довольно трудной задачей, во многом определяет результаты прогнозирования. В результате предварительного анализа (из физических условий задачи) выбирается класс функций, которыми может быть описано изучаемое явление. Параметры этих функций подлежат определению. В ряде случаев параметры функций могут иметь определенный физический или экономический смысл. Для процедуры прогнозирования при выборе сглаживающей функции надо иметь в виду следующее: функция должна отражать основную закономерность развития явления, в отношении которой можно выдвинуть гипотезу, что эта закономерность сохранится и в будущем. Тогда как, например, для процесса интерполяции достаточно, чтобы выбранная функция наиболее близко описывала значения ряда.
Для сглаживания рядов динамики нецелесообразно брать функции с большим числом параметров, в то же время выбранная функция должна быть адекватна исследуемому процессу. Следует иметь в виду, что короткие ряды в редких случаях дают возможность получить объективную информацию. После определения параметров выбранных функций из них надо выбрать наиболее приемлемую. Знание оценок свободных параметров функций и их дисперсий дает возможность применить критерии согласия для выбора основной функции. Процесс сглаживания требует тщательного анализа, чтобы исключить возможность «сгладить» под видом случайных выбросов и отклонений существенные кратковременные изменения показателей, отражающих важные моменты в поведении системы.
В большинстве случаев динамический ряд, кроме тренда и случайных отклонений от него, характеризуется еще сезонными и циклическими составляющими. Циклические составляющие отличаются от сезонных большей продолжительностью и непостоянством амплитуды. Обычная продолжительность сезонной компоненты измеряется днями, неделями или месяцами, а циклической — годами или десятками лет.
2.4. Методы анализа временных рядов.
В ПРИМЕРАХ, КОТОРЫЕ БУДУТ РАССМОТРЕНЫ НИЖЕ, ТРЕНД ЯВЛЯЕТСЯ ЛИНЕЙНЫМ.
Это означает, что модель тренда легко построить, используя для расчета параметров прямой, наилучшим образом аппроксимирующий данный тренд, метод регрессии. Затем данная модель может использоваться для прогнозирования будущих значений тренда. В действительности, тренд в чистом виде либо не существует, например, при колебании значений спроса вокруг некоторой фиксированной величины, либо в большинстве случаев он является нелинейным.
При рассмотрении того, как работают эти методы, мы будем пользоваться одним и тем же моментным временным рядом.
ПРИМЕР 1. Предположим, что объемы продаж товара в течение недели описываются следующим временным рядом (рис. 9).
|
День недели |
Количество проданной продукции |
|
Понедельник |
10 |
|
Вторник |
6 |
|
Среда |
5 |
|
Четверг |
11 |
|
Пятница |
9 |
|
Суббота |
8 |
|
Воскресенье |
7 |
Рис. 9. Моментный временной ряд.
Этот временной ряд можно задать в более формализованном виде (рис. 10).
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
x |
10 |
6 |
5 |
11 |
9 |
8 |
7 |
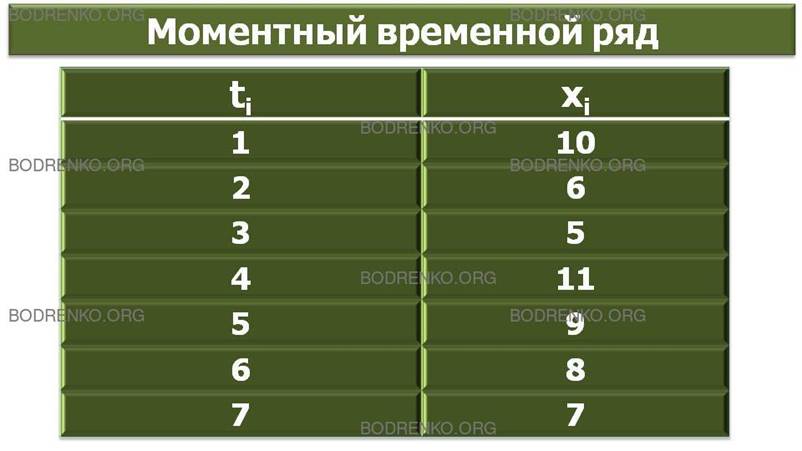
Рис. 10. Моментный временной ряд.
1)
Метод
подвижного (скользящего) среднего.
Метод простого скользящего среднего (simple moving average) состоит в том, что расчет показателя на прогнозируемый момент времени строится путем усреднения значений этого показателя за несколько предшествующих моментов времени.
Практически во всех применяемых в настоящее время методах прогнозирования коэффициенты моделей сначала определяются путем подгонки модели к некоторым данным предыстории, а затем проверяются и уточняются по мере поступления новых данных.
В методе простого скользящего среднего первоначальные значения элементов ряда заменяются средним арифметическим значением внутри выбранного интервала. Полученное значение относится к середине выбранного интервала. Затем интервал сдвигается на одно наблюдение и расчет скользящего среднего повторяется. Интервалы определения скользящего среднего берутся все время одинаковыми. Чем шире интервал, тем более плавным получается новый ряд. Сглаженный ряд короче первоначального на (N—1) наблюдений, где N — величина интервала сглаживания.
Выбор интервала сглаживания определяется конкретной задачей. Если число членов интервала сглаживания нечетное, то полученные значения скользящего среднего приходятся на средний член интервала сглаживания. При четном числе членов интервала сглаживания значения скользящих средних будут располагаться в промежутках между элементами ряда.
Обратимся к временному ряду (рис. 10), заданному в примере 1.
Для вычисления прогнозируемого объема продаж на четверг поступим следующим образом. Возьмем фактические данные за три предыдущих дня – понедельник, вторник и среду — и найдем их среднее арифметическое:
![]()
Прогнозируемый объем продаж на пятницу вычисляется аналогичным образом по реальным показателям за три предшествующих дня — вторник, среду и четверг:
![]()
Подобным же способом рассчитываются прогнозы на субботу, воскресенье и очередной понедельник:
![]()
![]()
![]()
И мы получаем следующую таблицу (рис. 11):
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
x |
10 |
6 |
5 |
11 |
9 |
8 |
7 |
– |
|
f |
– |
– |
– |
7 |
7,33 |
8,33 |
9,33 |
8 |
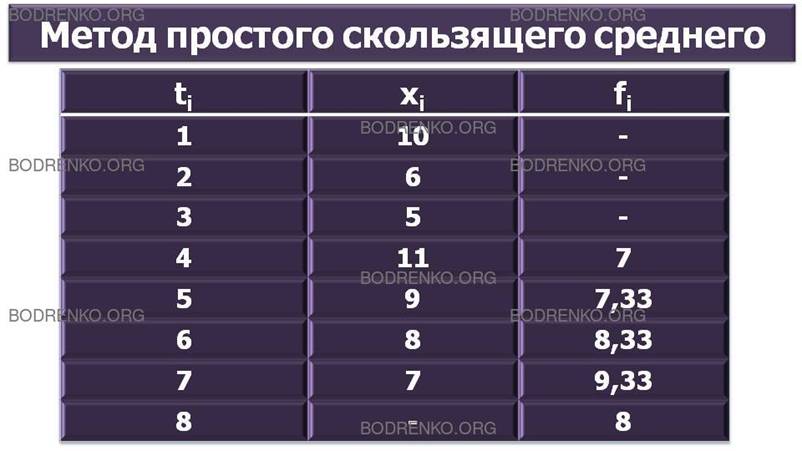
Рис. 11. Прогнозирование объема продаж.
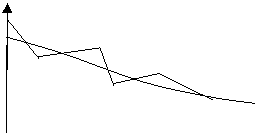
Сравнительные результаты приведены на рис. 12: сплошными линиями соединены реальные значения, а пунктирными — прогнозируемые.
![]()

![]()
![]()
![]()
![]()
 10
10
![]()
![]() -
-
![]()
![]()
![]() 8
8
![]() -
-
![]() 6
6
-
4
-
2
-
![]()
1 2 3 4 5 6 7 8
Рис. 12. Сравнение реальных и прогнозируемых показателей.
Для общего случая расчетная формула выглядит так:
![]()
или
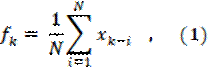
где xk-i — реальное значение показателя в момент времени tk-i, N — число предшествующих моментов времени, используемых при расчете; fk — прогноз на момент времени tk.
Замечание. В рассматриваемом примере N = 3.
Простота и наглядность — достоинства метода простого скользящего среднего. Но при малом числе наблюдений этот метод приводит к искажению тенденции, величина интервала сглаживания влияет на форму тренда, теряются начальные и конечные элементы ряда.
2)
Метод
взвешенного подвижного (скользящего) среднего (weighted moving average).
При составлении прогноза методом усреднения часто приходится наблюдать, что влияние используемых при расчете реальных показателей оказывается неодинаковым, при этом обычно более свежие данные имеют больший вес.
Математически метод взвешенного подвижного среднего можно описать формулой:
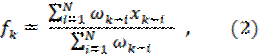
где xk-i — реальное значение показателя в момент времени tk-i, N — число предшествующих моментов времени, используемых при расчете; fk — прогноз на момент времени tk.
ωk-i — вес, с которым используется показатель xk-i при расчете.
ЗАМЕЧАНИЕ. Вес — это всегда положительное число. В случае, когда все веса одинаковы, мы получаем формулу (1).
Для расчетов обратимся к исходному временному ряду, считая, что при составлении прогноза на завтрашний день объем сегодняшних продаж мы возьмем с весом 60, вчерашних — с весом 30, а позавчерашних - с весом 10: ω3 = 60, ω2 = 30, ω1 = 10.
Мы имеем:
![]()
![]()
![]()
![]()
![]()
На рисунке 13 дается графическое представление проведенных расчетов: сплошными линиями соединены реальные значения, а пунктирными — прогнозируемые.
![]()
![]()
![]()
![]()
![]() 10 -
10 -
![]()
![]() -
-
![]()

![]()
![]() 8 -
8 -
-
![]() 6 -
6 -
-
4 -
-
2 -
-
![]()
1 2 3 4 5 6 7 8
Рис. 13. Сравнение реальных и прогнозируемых показателей.
Для стационарных рядов существует система весовых множителей, позволяющая обеспечить минимальную ошибку прогноза. Эти множители определяются видом автоковариационной функции. Известен метод вычисления таких оптимальных весовых функций для постоянного уровня, тренда и сезонных коэффициентов. В каждом из этих случаев весовые множители экспоненциально уменьшаются по закону αj, а различные значения α, получаемые для уровня, тренда и сезонных коэффициентов, определяются систематическими исследованиями точности прогнозов, получаемых при различных комбинациях весовых функций.
Во многих случаях целесообразно использовать последовательность ωj = αj, 0 < α <1, придающую более высокий вес более поздней информации и позволяющую относительно просто оценивать значения коэффициентов даже достаточно сложных моделей, таких, в которых для описания сезонных циклов используются полиномы в сочетании с преобразованиями Фурье (подобное представление можно рассматривать как сложные полиномы).
Для модели экспоненциально взвешенного скользящего среднего предложены способы, с помощью которых в те периоды времени, когда средняя ошибка прогноза близка к нулю (благодаря правильности модели и ее коэффициентов), скорость затухания α может быть увеличена; а в те периоды времени, когда средняя ошибка прогноза существенно отличается от нуля и существует опасность того, что модель может «забыть» старую информацию (в этом случае требуется уточнение прогноза), скорость затухания α может быть уменьшена.
Уточнение прогноза производится по принципу обратной связи — новые прогнозы корректируются на основе учета ошибок в предшествующих прогнозах. Если при выборе весовых множителей в процессе составления прогноза также используется обратная связь, то не только строгий анализ областей устойчивости данной системы, но и любой анализ вообще становится фактически невозможным. Для анализа эффективности какого-либо метода недостаточно привести примеры, подтверждающие его полезность. Необходимо также выявить области (если они существуют), в которых применение рассматриваемого метода невозможно или неэффективно.
3)
Метод
экспоненциального сглаживания.
3)
При расчете прогноза методом экспоненциального сглаживания (exponential smoothing) учитывается отклонение предыдущего прогноза от реального показателя, а сам расчет проводится по следующей формуле:
![]()
Где xk-1 — реальное значение показателя в момент времени tk fk — прогноз на момент времени tk; α — постоянная сглаживания.

ЗАМЕЧАНИЕ. Значение постоянной α, подчиненной условию 0 < α < 1 , определяет степень сглаживания и обычно выбирается универсальным методом проб и ошибок.
Для расчетов вновь обратимся к
исходному временному ряду, положив α
= 0,2 и считая, что прогноз на понедельник равен 8. Тогда находим
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Результаты расчетов приведены в таблице (рис. 14):
|
t |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
x |
10 |
6 |
5 |
11 |
9 |
8 |
7 |
– |
|
f |
– |
8,40 |
7,92 |
7,34 |
8,07 |
8,26 |
8,21 |
7,97 |
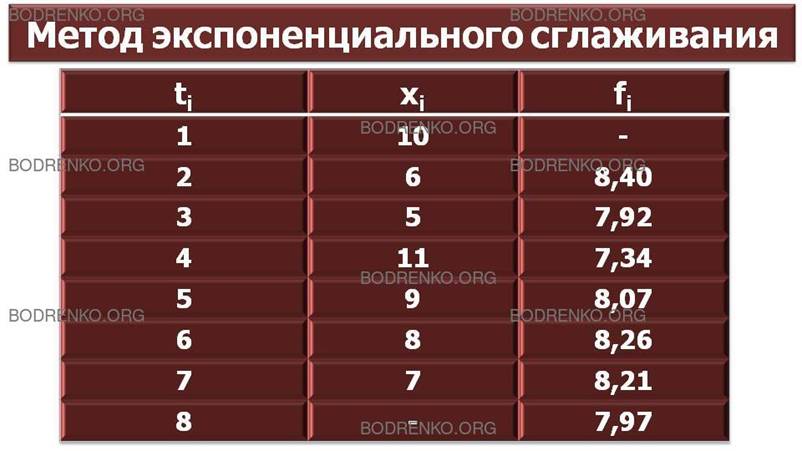
Рис. 14. Прогнозирование объема продаж.
На рисунке 15 дается графическое представление проведенных расчетов (сплошными линиями соединены реальные показатели, пунктирными — прогнозируемые).
![]()


![]()
 10 -
10 -
![]()
![]()
![]()
![]()
![]() -
-
![]()
![]()
![]()
![]()
![]()
![]() 8 -
8 -
![]()
![]() -
-
![]() 6 -
6 -
-
4 -
-
2 -
-
![]()
![]() 1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
Рис. 15. Сравнение реальных и прогнозируемых показателей.
Метод экспоненциального сглаживания разработан для рядов, состоящих из большого числа наблюдений, при увеличении числа наблюдений точность прогноза должна возрастать. При анализе коротких рядов метод не «срабатывает», так как часто не «успевает» отразить изменения при быстрых темпах роста. Если явление протекает в одних и тех же условиях, то точность прогноза определяется величиной периода предистории явления (базисного периода) и длительности прогнозируемого периода. Количественно это влияние можно оценить по имеющемуся ряду динамики, если одну часть ряда рассматривать как предисторию, а вторую — как прогнозируемую. Получив прогнозирующую функцию по базисному периоду, по второй части ряда можно оценить реальные ошибки прогноза. Изменяя число элементов рядов предистории и прогноза, получим зависимость точности прогноза от периода предистории и величины прогнозируемого периода.
ЗАМЕЧАНИЕ. Следует иметь в виду, что при решении реальной задачи прогнозирования временной ряд складывается постепенно и реальное значение показателя на рассчитываемый момент времени нам заранее неизвестно. Прежде чем «заглянуть в будущее» посредством одного из указанных выше методов, обычно проводят расчеты с полным временным рядом, описывающим некоторый промежуток времени в прошлом. Это делается для того, чтобы подобрать подходящее значение N и сравнить результаты прогноза с реальными данными (метод простого скользящего среднего), подобрать подходящие значения N и весов и сравнить результаты прогноза с реальными данными (метод взвешенного скользящего среднего), подобрать подходящие значения постоянной сглаживания α и сравнить результаты прогноза с реальными данными (метод экспоненциального сглаживания).
4)
Метод
проецирования тренда.
Тренды могут быть описаны различными уравнениями — линейными, логарифмическими, степенными и т. д. Фактический тип тренда устанавливают на основе подбора его функциональной модели статистическими методами либо сглаживанием исходного временного ряда. Выделяют тренды восходящий (бычий), нисходящий (медвежий) и боковой (флэт). На графике часто рисуют линию тренда, которая на восходящем тренде соединяет две или более впадины цены (линия находится под графиком, визуально «поддерживая и подталкивая» график вверх), а на нисходящем тренде соединяет два или более пика цены (линия находится над графиком, визуально «ограничивая и придавливая» график вниз). Трендовые линии являются «линиями поддержки» (для восходящего тренда) или «линиями сопротивления» (для нисходящего тренда).
Основной идеей метода проецирования линейного тренда (trend projection) является построение прямой, которая «в среднем» наименее уклоняется от массива точек (ti, xi), i = 1,2,...,n, заданного временным рядом (рис. 16).
Эта прямая ищется в следующем виде:
x = at + b, (3)
где а и b — постоянные, подлежащие определению.
![]() x
x
![]()
 x=at+b
x=at+b
![]()
![]() xi
xi
![]()
![]()
![]()
![]() x1
x1

t1 t2 ti … tn t
Рис. 16. Метод проецирования тренда.
Чтобы найти коэффициенты а и b, поступают так: для каждого значения ti; переменной t, пользуясь формулой (3), вычисляют соответствующее значение переменной х, затем находят разность (ati + b – xi), которую затем возводят в квадрат (чтобы не думать о знаке):
(ati + b – xi)2 (i =1, …, n) и, складывая, в итоге получают:
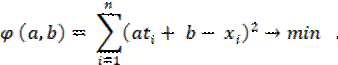
Функция φ (a, b) принимает минимальное значение в том случае, когда величины a и b удовлетворяют следующей линейной системе:
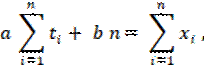
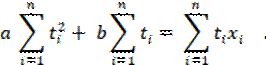

Эта система всегда имеет единственное решение.
Рассмотрим конкретный пример, вновь обратившись к заданному временному ряду (рис. 10).
ПРИМЕР.
Составим вспомогательную таблицу (рис. 17).
|
ti |
xi |
ti xi |
ti2 |
|
1 |
10 |
|
1 |
|
2 |
6 |
|
4 |
|
3 |
5 |
|
9 |
|
4 |
11 |
|
16 |
|
5 |
9 |
|
25 |
|
6 |
8 |
|
36 |
|
7 |
7 |
|
49 |
|
∑ ti
= 28 |
∑ xi = 56 |
∑ ti xi = 223 |
∑ ti2= 140 |
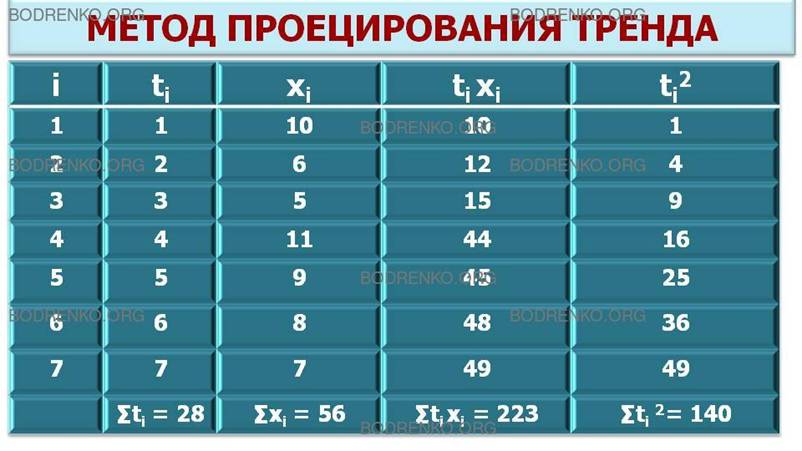
Рис. 17. Таблица для расчета коэффициентов уравнения тренда.
В этом случае система уравнений для отыскания a и b записывается в следующем виде:
28 a + 7 b = 56;
140 a + 28 b = 223.
Решая систему, получаем:
a = (– 1/28) ≈ - 0,04; b = 57/7 ≈ 8,14.

Тем самым уравнение искомого тренда имеет вид: x = – 0,04 t + 8,14.
Расчет показателя на следующий день проводится так:
![]()
Графическое изображение тренда представлено на рисунке 18.
![]()


![]() 11 -
11 -
![]()
 10 -
10 -
![]()
![]()
![]() -
-
![]()
![]()
![]()
![]() 8 -
8 -
![]()
![]() -
-
![]() 6 -
6 -
-
4 -
-
2 -
-
![]()
![]() 1 2 3 4 5 6 7 8
1 2 3 4 5 6 7 8
Рис. 18. Метод проецирования тренда.
ЗАМЕЧАНИЕ. Точность прогноза можно оценить при помощи коэффициента корреляции.
Приведенные методы далеко не исчерпывают многообразия методов анализа временных рядов, большинство которых опирается не на простой подсчет при помощи калькулятора, но на основательную аналитическую и компьютерную базу. Однако наша цель состоит в том, чтобы дать определенное рабочее представление об этом типе прогнозирования.
3. ТРЕНДОВЫЕ МОДЕЛИ, СОДЕРЖАЩИЕ СЕЗОННУЮ КОМПОНЕНТУ.
В большинстве случаев значения переменных характеризуют не только тренд. Часто они подвержены циклическим колебаниям. Если эти колебания повторяются в течение небольшого промежутка времени, то они называются сезонной вариацией. Колебания, повторяющиеся в течение более длительного промежутка времени, называются циклической вариацией.
Модель, содержащая сезонную компоненту, которая будет рассмотрена на этой лекции, основана на традиционном понятии сезона, однако, в более широком смысле термин «сезон» в прогнозировании применим к любым систематическим колебаниям.
Например, при изучении товарооборота в течение недели под термином «сезон» подразумевается 1 день. При исследовании транспортных потоков дня или в течение недели также может использоваться модель с сезонной компонентой.
Любые колебания относительно тренда, построенного по годовым значениям некоторого показателя, можно описать в виде модели с циклической компонентой. Не будем рассматривать примеры с циклическим фактором. Этот фактор можно выявить только по данным за длительные промежутки времени в 10, 15 или 20 лет, однако в данном случае колебания значений тренда могут быть вызваны воздействием общеэкономических факторов. Остановимся подробнее на моделировании более коротких промежутков времени, и не будем учитывать воздействие циклической компоненты.
Последняя предпосылка нашей модели также следует из метода линейной регрессии. Она связана со значением ошибки, или остатка, т.е. той части значения наблюдения, которую нельзя объяснить с помощью построенной модели.
ВЕЛИЧИНУ ОШИБОК МОЖНО ИСПОЛЬЗОВАТЬ В КАЧЕСТВЕ МЕРЫ СТЕПЕНИ СООТВЕТСТВИЯ МОДЕЛИ ИСХОДНЫМ ДАННЫМ.
Обычно применяют два вида таких мер.
1) Cреднее абсолютное отклонение (mean absolute deviation — MAD) вычисляется по формуле:
![]()
где xi - фактические значения показателя, fi - прогнозные значения показателя.

Таким образом, MAD равно отношению суммы величин всех ошибок без учета их знака к общему числу наблюдений.
2) Среднеквадратическая ошибка (mean square error — MSE):
![]()

Таким образом, MSE представляет собой отношение суммы квадратов ошибок к общему числу наблюдений. Последняя из указанных мер резко возрастает при наличии высоких ошибок. В процессе анализа временного ряда мы стараемся определить все имеющиеся факторы и построить модель, которая соответствующим образом отражала бы их.
ПРИМЕР 2.
Предположим, что объем продаж продукции компании в течение последних 13 кварталов представлен в таблице (рис. 19).
|
Дата |
Количество проданной продукции (тыс. шт.) |
|
Январь – март 2012 года |
239 |
|
Апрель – июнь 2012 года |
201 |
|
Июль – сентябрь 2012 года |
182 |
|
Октябрь – декабрь 2012 года |
297 |
|
|
|
|
Январь – март 2013 года |
324 |
|
Апрель – июнь 2013 года |
278 |
|
Июль – сентябрь 2013 года |
257 |
|
Октябрь – декабрь 2013 года |
384 |
|
|
|
|
Январь – март 2014 года |
401 |
|
Апрель – июнь 2014 года |
360 |
|
Июль – сентябрь 2014 года |
335 |
|
Октябрь – декабрь 2014 года |
462 |
|
|
|
|
Январь – март 2015 года |
481 |
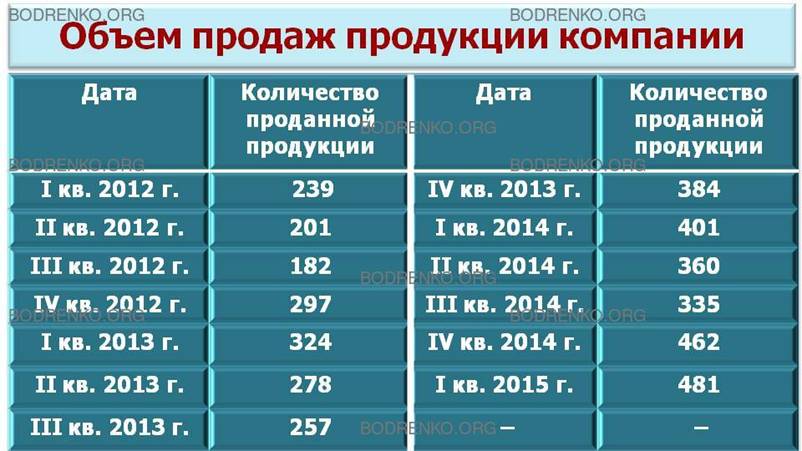
Рис. 19. Количество продукции, проданной в течение последних 13 кварталов.
Необходимо проанализировать указанное множество данных и установить, можно ли обнаружить тенденцию. Если устойчивая тенденция действительно существует, данная модель будет использоваться нами для прогнозирования количества проданной продукции в следующие кварталы. Составим диаграмму временного ряда (рис. 20).
Объем продаж
![]()
![]()
![]()
![]()
![]() 500 -
500 -
![]()
![]()
![]()
![]()
![]() 400
-
400
-
![]()

![]()
![]()
![]()
![]() 300
-
300
-
![]()
![]()
![]()
![]() 200
-
200
-
![]()
100 -
![]()
1 2
3 4 1
2 3 4
1 2 3
4 1 Время
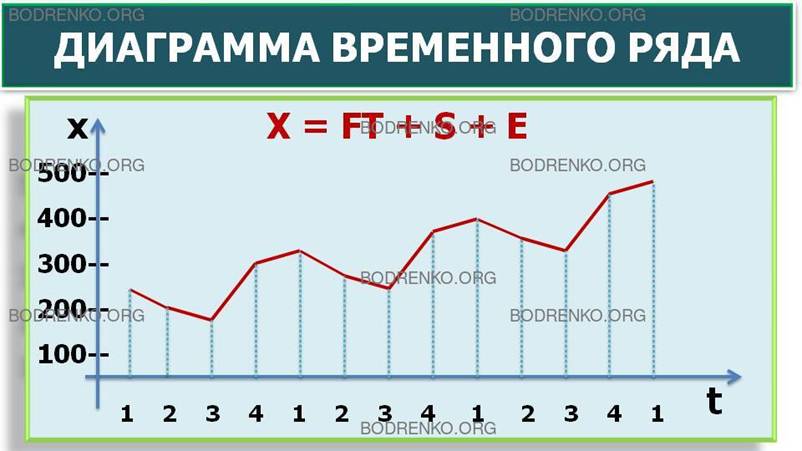
Рис. 20. Диаграмма временного ряда.
Моделью с аддитивной компонентой называется такая модель, в которой вариация значений переменной во времени наилучшим образом описывается через сложение отдельных компонент.
Предположив, что циклическая вариация не учитывается, модель фактических значений переменной X можно представить следующим образом: X = FT + S + Е, где X – фактическое значение, FТ – трендовое значение, S – сезонная вариация, E – ошибка.
ЗАМЕЧАНИЕ. Приблизительно равная сезонная вариация (рис. 20) указывает на существование аддитивной модели.
РЕШЕНИЕ.
Будем использовать диаграмму моментного временного ряда. При построении диаграммы временного ряда полезно последовательно соединить точки отрезками, чтобы более четко увидеть любую тенденцию. Как следует из диаграммы (рис. 20), возможен возрастающий тренд, содержащий сезонные колебания. Объемы продаж в зимний период (1 и 4 кварталы) значительно выше, чем в летний (2 и 3 кварталы). Сезонная компонента практически не изменится в течение трех лет. Тренд показывает, что в целом объем продаж возрос примерно с 230 тыс. шт. в 2012 году до 390 тыс. шт. в 2014 году, однако увеличения сезонных колебаний не произошло. Этот факт свидетельствует в пользу модели с аддитивной компонентой.
Проведем анализ модели с аддитивной компонентой: X = FT +S + E. В моделях, как с аддитивной, так и с мультипликативной компонентой, общая процедура анализа примерно одинакова:
Шаг 1. Расчет значений сезонной компоненты.
Шаг 2. Вычитание сезонной компоненты из фактических значений. Этот процесс называется десезонализацией данных. Расчет тренда на основе полученных десезонализированных данных.
Шаг 3. Расчет ошибок как разности между фактическими и трендовыми значениями.
Шаг 4. Расчет среднего отклонения (MAD) или среднеквадратической ошибки (MSE) для обоснования соответствия модели исходным данными или для выбора из множества моделей наилучшей.
1) Расчет сезонной компоненты в аддитивных
моделях.
ПРИМЕР 2 (продолжение). Вернемся к примеру 2, в котором рассматриваются квартальные объемы продаж компании за последние 13 кварталов. Мы уже выяснили, что этим данным отвечает аддитивная модель, т.е. фактически объемы продаж можно выразить следующим образом: X = FT + S + Е.
Для того чтобы элиминировать влияние сезонной компоненты, воспользуемся методом скользящего среднего.
Просуммировав первые четыре значения, получим общий объем продаж в 2012 году. Если поделить эту сумму на четыре, можно найти средний объем продаж в каждом квартале 2012 года, т. е.
(239 + 201 + 182 + 297)/4 = 919/4 = 229,75.
Полученное значение уже не содержит сезонной компоненты, поскольку представляет собой среднюю величину за год. У нас появилась оценка значения тренда для середины года, т.е. для точки, лежащей в середине между кварталами II и III.
Если последовательно передвигаться вперед с интервалом в три месяца, можно рассчитать средние квартальные значения на следующих промежутках.
апрель 2012 года — март 2013 года:
(201 + 182 + 297 + 324)/4 = 1004/4 = 251,
июль 2012 – июнь 2013:
(182 + 297 + 324 + 278)/4 = 1081/4 = 270,25;
…
апрель 2014 года - март 2015 года:
(360 + 335 + 462 + 481)/4 = 1638/4 = 409,5.

Данная процедура позволяет генерировать скользящие средние по четырем точкам для исходного множества данных. Получаемое таким образом множество скользящих средних представляет наилучшую оценку искомого тренда. Теперь полученные значения тренда можно использовать для нахождения оценок сезонной компоненты.
Мы рассчитываем: X – FT = S + E.
К сожалению, оценки значений тренда, полученные в результате расчета скользящих средних по четырем точкам, относятся к несколько иным моментам времени, чем фактические данные.
Первая оценка, равная 229,75, представляет собой точку, совпадающую с серединой 2012 года, т.е. лежит в центре промежутка фактических значений объемов продаж во II и III кварталах. Вторая оценка, равная 251, лежит между фактическими значениями в III и IV кварталах 2012 года.
НАМ ЖЕ ТРЕБУЮТСЯ ДЕСЕЗОНАЛИЗИРОВАННЫЕ СРЕДНИЕ ЗНАЧЕНИЯ, СООТВЕТСТВУЮЩИЕ ТЕМ ЖЕ ИНТЕРВАЛАМ ВРЕМЕНИ, ЧТО И ФАКТИЧЕСКИЕ ЗНАЧЕНИЯ ЗА КВАРТАЛ.
Положение десезонализированных средних во времени сдвигается путем дальнейшего расчета средних для каждой пары значений.
Найдем среднюю из первой и второй оценок, центрируя их на июль-сентябрь 2012 года, т. е.
(229,75 + 251) / 2 = 240,375 ≈ 240,4.
Это и есть десезонализированная средняя за июль-сентябрь 2012 года.
Эту десезонализированную величину, которая называется центрированной скользящей средней, можно непосредственно сравнивать с фактическим значением за июль-сентябрь 2012 года, равным 182.
Отметим, что это означает отсутствие оценок тренда за первые два или последние два квартала временного ряда. Результаты этих расчетов приведены в следующей таблице (рис. 21).
|
Дата |
Объем продаж |
Итого за четыре квартала |
Скользящее среднее за четыре квартала |
Центрированное скользящее среднее |
Оценка сезонной компоненты X – FT= S –E |
|
Январь – март 2012 г. |
239 |
919 (начиная с января 2012 г.) |
229,75 |
--- |
--- |
|
Апрель – июнь 2012 г. |
201 |
1004 (начиная с апреля 2012 г.) |
251 |
--- |
--- |
|
Июль – сентябрь 2012 г. |
182 |
1081(начиная с июля 2012 г.) |
270,25 |
240,4 |
–
58,4 |
|
Октябрь – декабрь 2012 г. |
297 |
1156 (начиная с октября 2012 г.) |
289 |
260,6 |
+ 36, 4 |
|
Январь – март 2013 г. |
324 |
1243 (начиная с января 2013 г.) |
310,75 |
279,6 |
+ 44,4 |
|
Апрель – июнь 2013 г. |
278 |
1320 (начиная с апреля 2013 г.) |
330 |
299,9 |
– 21,9 |
|
Июль – сентябрь 2013 г. |
257 |
1402 (начиная с июля 2013 г.) |
350,5 |
320,4 |
–
63,4 |
|
Октябрь – декабрь 2013 г. |
384 |
1480 (начиная с октября 2013 г.) |
370 |
340,3 |
+ 43,8 |
|
Январь – март 2014 г. |
401 |
1558 (начиная с января 2014 г.) |
389,5 |
360,3 |
+ 40,8 |
|
Апрель – июнь 2014 г. |
360 |
1638 (начиная с апреля 2014 г.) |
409,5 |
379,8 |
– 19,8 |
|
Июль – сентябрь 2014 г. |
335 |
--- |
--- |
399,5 |
– 64,5 |
|
Октябрь – декабрь 2014 г. |
462 |
--- |
--- |
--- |
--- |
|
Январь – март 2015 г. |
481 |
--- |
--- |
--- |
--- |
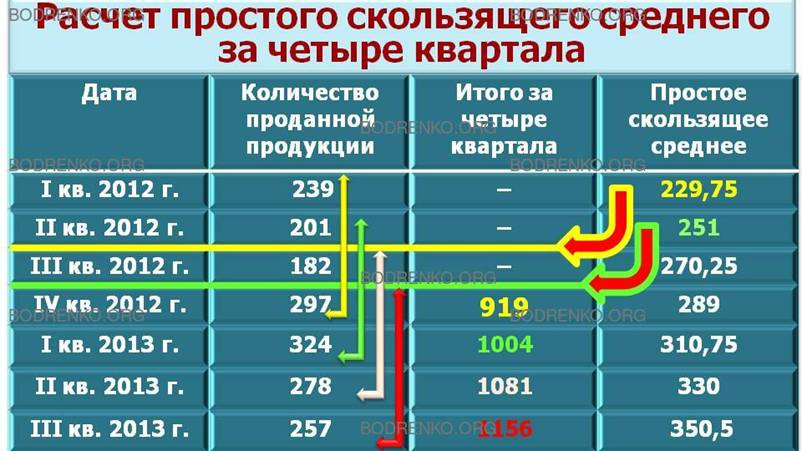


Рис. 21. Расчет по 4 точкам центрированных скользящих средних значений тренда для модели X= FT + S + Е.
Для каждого квартала мы имеем оценки сезонной компоненты, которые включают в себя ошибку или остаток. Прежде чем мы сможем использовать сезонную компоненту, нужно пройти два следующих этапа. Найдем средние значения сезонных оценок для каждого сезона года. Эта процедура позволит уменьшить некоторые значения ошибок. Наконец, скорректируем средние значения, увеличивая или уменьшая их на одно и то же число таким образом, чтобы общая их сумма была равна нулю. Это необходимо, чтобы усреднить значения сезонной компоненты в целом за год. Корректирующий фактор рассчитывается следующим образом: сумма оценок сезонных компонент делится на 4.
В последнем столбце таблицы (рис.
21) эти оценки записаны под соответствующими квартальными значениями. Сама
процедура приведена в следующей таблице (рис. 22).
|
|
Год |
Номер квартала |
|
|||
|
1 |
2 |
3 |
4 |
|
||
|
2012 |
--- |
--- |
-58,4 |
+36,4 |
|
|
|
2013 |
+44,4 |
-21,9 |
-63,4 |
+43,8 |
|
|
|
2014 |
+40,8 |
-19,8 |
-64,5 |
--- |
|
|
|
Итого |
|
+85,2 |
-41,7 |
-186,3 |
+80,2 |
|
|
Среднее значение |
|
+ 85,2 ÷ 2 |
-41,7÷ 2 |
-186,3 ÷ 3 |
+80,2÷2 |
|
|
Оценка сезонной компоненты |
|
+42,6 |
-20,8 |
-62,1 |
+40,1 |
Сумма: -0,2 |
|
Скорректированная сезонная компонента |
|
+42,6 |
-20,7 |
-62,0 |
+40,1 |
Сумма: 0 |
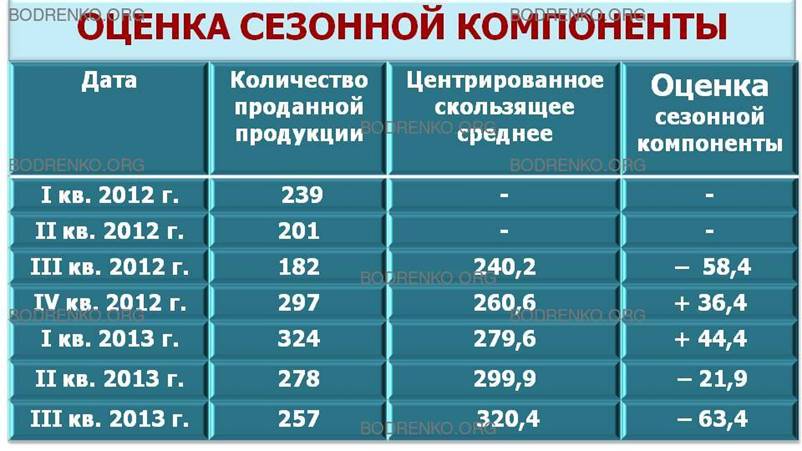
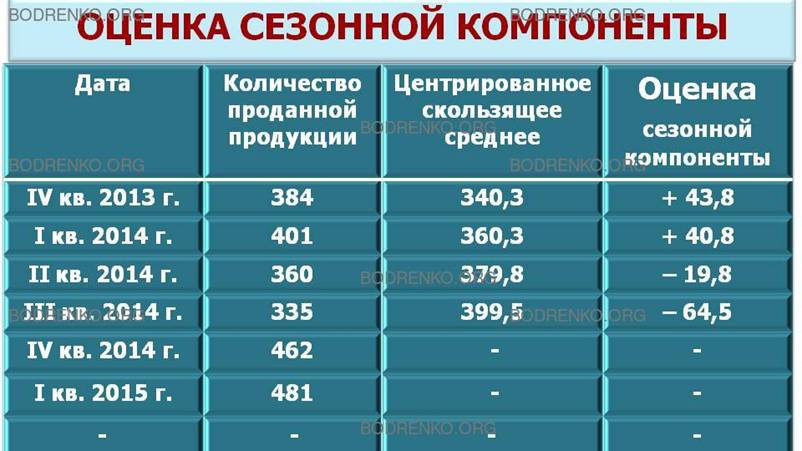

Рис. 22. Расчет средних значений сезонной компоненты.
В данном случае производилось округление двух значений сезонной компоненты до ближайшего большего числа, а двух значении — до ближайшего меньшего числа таким образом, чтобы общая сумма была равна нулю.
Значения сезонной компоненты еще раз подтверждают наши выводы, сделанные на основе диаграммы (рис. 20). Объемы продаж за два зимних квартала превышают среднее трендовое значение приблизительно на 40 тыс. шт., а объемы продаж за два летних периода ниже средних на 21 и 62 тыс. шт. соответственно.
ЗАМЕЧАНИЕ. Аналогичная процедура применима при определении сезонной вариации за любой промежуток времени. Если, например, в качестве сезонов выступают дни недели, для элиминирования влияния ежедневной «сезонной компоненты» также рассчитывают скользящую среднюю, но уже не по четырем, а по семи точкам. Эта скользящая средняя представляет собой значение тренда в середине недели, т.е. в четверг; таким образом, необходимость в процедуре центрирования отпадает.
2) Десезонализация данных при расчете тренда.
Шаг 2. Состоит в десезонализации исходных данных. Она заключается в вычитании соответствующих значений сезонной компоненты из фактических значений данных за каждый квартал (то есть X — S = FT + Е), что показано ниже (рис. 23).
|
Дата |
Номер квартала |
Количество проданной продукции |
Сезонная компонента S |
X – S =FT + E |
|
Январь – март 2012 года |
1 |
239 |
+42,6 |
196,4 |
|
Апрель – июнь 2012 года |
2 |
201 |
-20,7 |
221,7 |
|
Июль – сентябрь 2012 года |
3 |
182 |
-62,0 |
244 |
|
Октябрь – декабрь 2012 года |
4 |
297 |
+40,1 |
256,9 |
|
|
|
|
|
|
|
Январь – март 2013 года |
1 |
324 |
+42,6 |
281,4 |
|
Апрель – июнь 2013 года |
2 |
278 |
-20,7 |
298,7 |
|
Июль – сентябрь 2013 года |
3 |
257 |
-62,0 |
319 |
|
Октябрь – декабрь 2013 года |
4 |
384 |
+40,1 |
343,9 |
|
|
|
|
|
|
|
Январь – март 2014 года |
1 |
401 |
+42,6 |
358,4 |
|
Апрель – июнь 2014 года |
2 |
360 |
-20,7 |
380,7 |
|
Июль – сентябрь 2014 года |
3 |
335 |
-62,0 |
397 |
|
Октябрь – декабрь 2014 года |
4 |
462 |
+40,1 |
421,9 |
|
|
|
|
|
|
|
Январь – март 2015 года |
1 |
481 |
+42,6 |
438,4 |
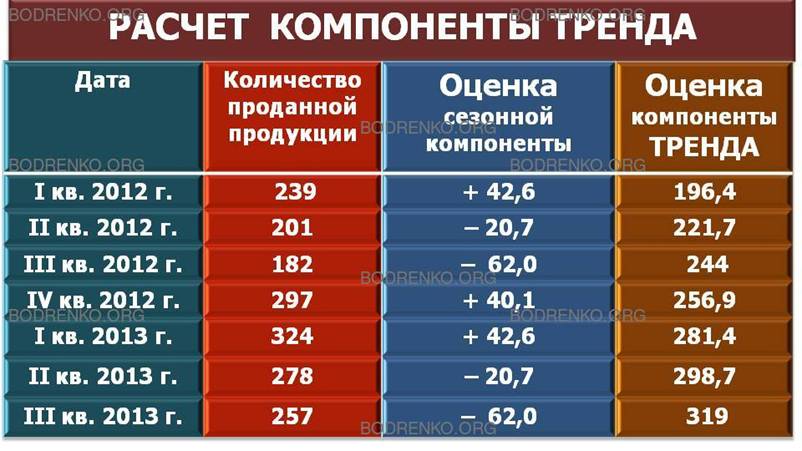
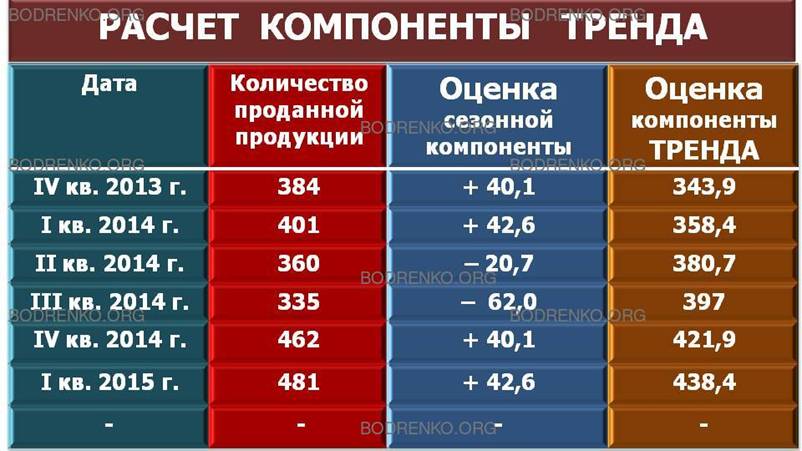
Рис. 23. Расчет десезонализированных
данных.
Новые оценки значений тренда, которые еще содержат ошибку, можно использовать для построения модели основного тренда. Если нанести эти значения на исходную диаграмму (рис. 24), можно сделать вывод о существовании явного линейного тренда.
![]()
![]()
![]()
![]() Объем продаж
Объем продаж
![]()
![]()
![]()
![]()
![]()
![]() 400
-
400
-
![]()

![]()
![]()
![]()
![]() 300
-
300
-
![]()
![]()
![]()
![]() 200
-
200
-
![]()
100 -
![]() 1 2
3 4 1
2 3 4
1 2 3
4 1 Время
1 2
3 4 1
2 3 4
1 2 3
4 1 Время
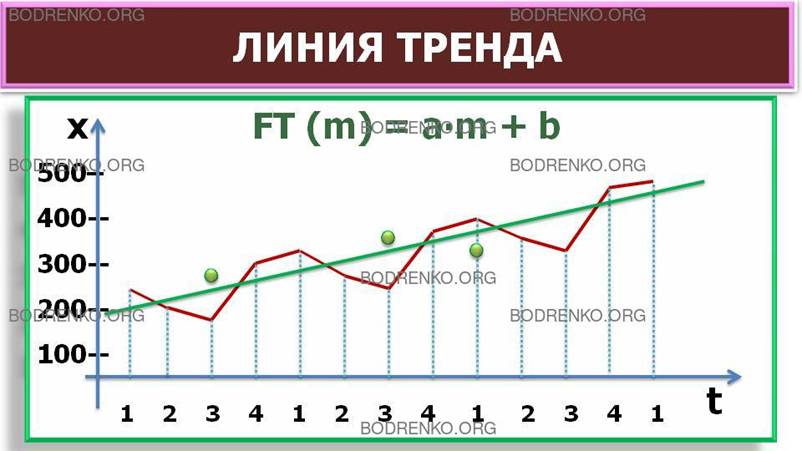
Рис. 24. Графическое изображение линии тренда.
Уравнение линии тренда имеет вид: FТ (m) = аm + b, где m — номер квартала; коэффициенты a и b характеризуют точку пересечения с осью ординат и угол наклона линии тренда к временной оси. Для определения параметров a, b прямой, наилучшим образом аппроксимирующей тренд, можно использовать метод наименьших квадратов.
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
[1] Грешилов
А. Α., Стакун В. Α., Стакун А. А. Математические методы построения прогнозов.— М.: Радио и
связь, 1997.— 112 с; ил.
[2] Шелобаев
С. И. Математические методы и модели в экономике, финансах, бизнесе: Учеб. пособие для вузов. —
М.: ЮНИТИ- ДАНА, 2001. - 367 с.

[3] Шикин Е.
В., Чхартишвили А. Г. Математические методы и модели в управлении: Учеб.
пособие. — 3-е изд. — М.: Дело, 2004. — 440 с. — (Сер. "Классический
университетский учебник").
[4] Эддоус М., Стенсфилд Р. Методы принятия решений. М.: ЮНИТИ, 1997.
[5]
Экономико-математические методы и прикладные модели: Учебное пособие для вузов/
В.В. Федосеев, А.Н. Гармаш, Д.М.
Дайитбегов и др.; Под ред. В.В. Федосеева. — М.: ЮНИТИ, 1999. - 391 с.
