Хранилища данных. Архитектура хранилищ данных. Подсистемы хранилища данных. Методология построения хранилищ данных. Структура хранилища данных. Модель типового проекта создания хранилища данных. Хранилища данных и системы бизнес-аналитики. Модели и методы добычи данных.
Решение задач и выполнение научно-исследовательских разработок: Отправьте запрос сейчас: irina@bodrenko.org
математика, IT, информатика, программирование, статистика, биостатистика, экономика, психология
Пришлите по e-mail: irina@bodrenko.org описание вашего задания, срок выполнения, стоимость
Хранилища данных
Лекция 4. Тема лекции:
«Архитектура хранилищ данных»

1.
Подсистемы
хранилища данных.
2.
Методология построения хранилищ данных.
3.
Структура
хранилища данных.

1. ПОДСИСТЕМЫ ХРАНИЛИЩА ДАННЫХ.
Хранилище
данных на самом верхнем уровне состоит, как правило, из трех подсистем:
1)
подсистема загрузки данных,
2)
подсистема обработки запросов и
представления данных,
3)
подсистема администрирования хранилища данных.

ПОДСИСТЕМА ЗАГРУЗКИ ДАННЫХ.
Данная
подсистема представляет собой ПО, которое в соответствии с определенным
регламентом извлекает данные из источников и приводит их к единому формату,
определенному для хранилища. Данная подсистема отвечает за формализованную
логическую согласованность, качество и интеграцию данных, которые загружаются
из источников в оперативный склад данных. Каждый источник данных требует
разработки собственного загрузочного модуля.
Каждый
загрузочный модуль должен решать два класса задач:
1-й
класс задач. Начальная загрузка ретроспективных
данных.
2-й
класс задач. Регламентное пополнение хранилища
данными из источников.
Данная подсистема также по регламенту
извлекает детальные данные из оперативного склада, производит их агрегирование,
консолидацию, трансформацию и помещает данные в хранилище и витрины данных.
Именно в данной подсистеме должны быть определены все бизнес-модели
консолидации данных по иерархическим измерениям и вычисления зависимых
бизнес-показателей по независимым исходным данным.
ПОДСИСТЕМА ОБРАБОТКИ ЗАПРОСОВ И ПРЕДСТАВЛЕНИЯ ДАННЫХ.
Оперативный
склад, хранилище и витрины данных являются инфраструктурой, которая
обеспечивает хранение и администрирование данных. Для извлечения данных, их
аналитической обработки и представления конечным пользователям служит
специальное ПО.
Как
правило, можно выделить три типа данного ПО:
1-й тип ПО.
Программное обеспечение регламентированной отчетности. Это ПО характеризуется заранее предопределенными
запросами данных и их представлениями бизнес-пользователям. От данного ПО не
требуется быстрого времени реакции. Из соображений стоимости эффективности для
его реализации в наибольшей степени подходит технология ROLAP (см.: лекция
3 «Аналитическая обработка данных при помощи хранилища данных»).
2-й
тип ПО. Программное
обеспечение нерегламентированных запросов пользователей. Это ПО – основной
способ общения бизнес-аналитиков с хранилищем, при котором каждый последующий
запрос к данным и вид их представления определяются, как правило, результатами
предыдущего запроса. Для приложений данного типа требуется высокая скорость
обработки запросов (единицы секунд). Данное ПО реализуется технологией MOLAP (см.: лекция 3 «Аналитическая обработка
данных при помощи хранилища данных») и специальными инструментами построения
сложных нерегламентированных запросов с интуитивно понятным для бизнес-аналитиков
графическим интерфейсом.
3-й
тип ПО. Программное
обеспечение добычи знаний (Data Mining). Это ПО реализует сложные статистические алгоритмы и
алгоритмы искусственного интеллекта, предназначенные для поиска скрытых в
данных закономерностей, представления этих закономерностей, представления этих
закономерностей в виде моделей и многовариантного прогнозирования по ним
развития ситуаций по схеме «Что если …?».
Конечно,
как правило, такое деление носит весьма условный характер, а границы между соответствующими
приложениями могут быть размыты.
ПОДСИСТЕМА АДМИНИСТРИРОВАНИЯ ХРАНИЛИЩА ДАННЫХ.
К
ведению данной подсистемы относятся все задачи, связанные с поддерживанием
системы и обеспечением ее устойчивой работы и расширения.
Можно
выделить, по крайней мере, четыре класса задач, решение которых должна
обеспечивать данная подсистема:
1.
Администрирование данных, которое
включает в себя регулярное пополнение данных из источников, если необходимо,
ручной ввод, сверка и корректировка данных в оперативном складе.
Администрирование данных ведется, как правило, бизнес-пользователями, а
ответственность распределяется по предметно-ориентированным сегментам.
2.
Администрирование хранилища данных. В
задачу администрирования хранилища входят все вопросы, связанные с поддержанием
архитектуры хранилища данных, его эффективной и бесперебойной работы, защитой и
восстановлением данных после сбоев.
3.
Администрирование доступа к данным
обеспечивает сопровождение профилей пользователей, разграничение доступа к
конфиденциальным данным, защиту информации от несанкционированного доступа.
4.
Администрирование метаданных системы.
2. МЕТОДОЛОГИЯ
ПОСТРОЕНИЯ ХРАНИЛИЩ ДАННЫХ.
Существуют
различные подходы к стратегии
построения корпоративного хранилища данных (ХД):
- построение сверху вниз;
- построение снизу вверх;
- динамическая интеграция данных и др.
Считается, что наиболее эффективным
подходом является подход, при котором в процессе разработки и внедрения
хранилища данных осуществляется его пошаговое наращивание на основе единой системы
классификаторов и общей среды передачи и хранения данных – спиральная модель
процесса разработки.
|
|
|
|
Спиральная
модель разработки. |
Стратегия
построения СППР. |

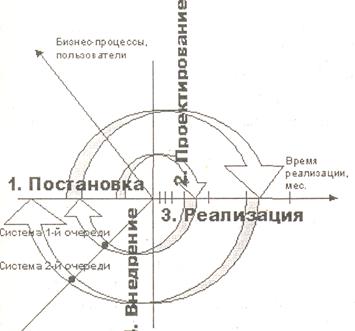
На каждом шаге развертывания
осуществляется реализация одной или ограниченного числа витрин данных по
следующему технологическому циклу (фазам создания):
- Постановка задачи.
- Проектирование.
- Реализация.
- Внедрение.

Стратегия
пошагового наращивания позволяет по завершении каждого цикла ввести в
кратчайшие сроки в промышленную эксплуатацию законченную систему, с определенной
ограниченной функциональностью. Небольшие масштабы каждого проектного цикла
существенно уменьшают потери при возможных проектных ошибках по сравнению с
полномасштабным проектированием и созданием системы в целом. Кроме того, поскольку
в каждом цикле применяются одни и те же методологические и технологические
подходы, а также средства разработки, то время реализации каждой новой витрины
будет сокращаться за счет повышения опыта проектной группы и постепенной отладки
механизма взаимодействия между заказчиком и разработчиком системы.
1.
ПОСТАНОВКА ЗАДАЧИ.
Системно-аналитическое обследование.
Этап
обследования начинается с согласования и утверждения заказчиком плана и
программы обследования. В процессе обследования выполняются следующие виды
работ:
- проводятся интервью с основными
участниками проекта со стороны компании-заказчика и лицами, ответственными за
принятие управленческих решений;
- уточняется организационная структура,
фиксируются организационные и функциональные рамки проекта;
- выявляются и документируются
особенности и недостатки существующих информационных решений;
- формализуется схема бизнеса компании
с учетом функциональных рамок;
- производится сбор существующих
отчетных материалов и прочих официальных документов, имеющих непосредственное
отношение к реализации проекта.
По
итогам обследования уточняются стратегические и оперативные задачи управления
компанией, решение которых должна обеспечивать СППР, формализуются цели и
задачи создания системы. Цель этапа
анализа – получение моделей данных и описание процедур принятия
управленческих решений.
Техническое задание.
Техническое задание (ТЗ)
– один из ключевых документов проекта, который определяет требования к созданию
СППР и порядок этого создания. Как правило, если время разработки
системы превышает двенадцать месяцев, то целесообразно вводить очередность и,
соответственно, сначала разрабатывать на основе концепции ТЗ систему первой
очереди, которая может быть реализована за 3 месяца. В противном случае
динамично развивающиеся условия бизнеса, постоянно совершенствующиеся
информационные технологии приведут к тому, что, когда полномасштабная система
будет реализована, она уже морально устареет. Если проект достаточно масштабен,
то помимо основного ТЗ на систему в целом могут разрабатываться и частные ТЗ на
ее отдельные компоненты.
2.
ПРОЕКТИРОВАНИЕ.
На
данной стадии проектных работ, на основе анализа требований к системе,
сформулированных в ТЗ, разрабатываются основные архитектурные решения.
Архитектура информационной системы
(ИС) рассматривается в четырех аспектах:
Логическая
архитектура. Представляет архитектуру системы с
точки зрения пакетов базовых классов и их взаимосвязей. Определяются автоматизируемые процессы и функции,
необходимые для достижения поставленных целей, которые затем разделяются на
задачи, подлежащие реализации на стадии разработки.
Архитектура
процессов. Применительно к СППР, определяет информационное обеспечение системы –
состав и содержание процессов преобразования и передачи данных.
Компонентная
архитектура. Представляет архитектуру ПО системы,
ее декомпозицию на подсистемы и компоненты.
Техническая
архитектура. Описывает физические узлы системы и
связи между ними.

1. Логическая архитектура СППР. Автоматизируемые процессы
и функции.
Система
Поддержки Принятия Решений (СППР) по виду автоматизированной деятельности
относятся к системам обработки и передачи информации. Объектами
автоматизации являются технические процессы, связанные с информационным
обеспечением управленческой и аналитической деятельности руководящего персонала
и специалистов подразделений и высшего руководства компании.
Целями
ССПР являются:
Интеграция ранее разъединенных
детализированных данных:
-
исторических архивов,
-
данных из оперативных систем,
- данных из внешних источников.
Разделение наборов данных,
используемых для оперативной обработки, и наборов данных, используемых для
решения задач поддержки принятия решений.
Обеспечение всесторонней информационной поддержки
максимальному кругу пользователей.
Для
реализации поставленных целей в рамках СППР подлежат автоматизации следующие процессы:
1.
Сбор данных.
2.
Преобразование
данных:
-
Очистка данных.
-
Согласование данных.
-
Унификация данных.
-
Агрегирование данных.
3.
Хранение
данных:
-
Промежуточное хранение данных.
-
Накопление исторических данных.
4.
Предоставление
данных потребителям.
2. Архитектура процессов. Информационное обеспечение СППР.
В общем случае информационное
обеспечение СППР состоит из пяти классов данных:
1)
источников данных,
2)
оперативного склада данных,
3)
хранилища данных,
4)
витрины данных,
5)
репозитария метаданных.
Проектирование
информационного обеспечения системы осуществляется сверху вниз. На основе
анализа прецедентов использования системы, выявленных на этапе системно-аналитического
обследования, определяются представления данных конечным прикладным
пользователям системы: состав показателей и их разрезы. Осуществляется
сегментация представлений данных в соответствии с их проблемной ориентацией. На
основе групп представлений витрин должны быть определены:
1.
Измерения,
их иерархии и уровень детализации. Например, для временного измерения должен
быть определен минимальный интервал времени (день, неделя, месяц), по которому
будут индексироваться показатели в витрине.
2.
Базовые
показатели, измерения, их индексирующие, и
правила агрегирования каждого показателя по иерархиям. Правила агрегирования по
иерархическому измерению зависят от показателя. Например, если для дохода от
продаж агрегирование по времени осуществляется простым суммированием, то при
исследовании цены продукции агрегирование по времени может быть реализовано в
виде среднего, максимального или минимального значения за период агрегации.
3.
Производные
показатели и формулы их вычисления на основе базовых
показателей.
Выбор конкретного способа представления
витрин (ROLAP,
MOLAP
или HOLAP — см. лекция 3) выполняется, как правило, на стадии реализации
системы.
Выявленные измерения и показатели
служат исходными данными для проектирования хранилища данных.
В
первую очередь обобщаются все выявленные разрезы и их иерархии. На их основе
проектируется бизнес-пространство хранилища. Измерения, как правило, тесно
связаны со структурированной нормативно-справочной информацией компании.
Например, измерениями хранилища часто служат организационная структура
компании, справочник административно-территориального деления, план финансовых
статей компании и пр.
На
пространстве, которое задается бизнес-измерениями, проектируются базовые и
производные показатели, которые должны находиться в хранилище. Для больших
систем целесообразно проводить сегментацию хранилища по предметным областям.
На
следующем этапе выполняется анализ результатов обследования источников данных.
При выборе подходящего источника во внимание принимаются следующие вопросы:
- Если имеется более одного источника, то
следует ли определить, какой из них лучше?
- Какие преобразования необходимо
выполнить, чтобы приготовить источник к загрузке в хранилище?
- Согласуются ли структура источника и
структура хранилища?
- Насколько согласуются данные
источника с нормативно-справочной информацией?
- Что будет происходить, если источник
имеет несколько месторасположений?
- Насколько аккуратны данные источника?
- Как источник обновляется?
- Каковы возраст и перспективность
источника?
- Насколько полны данные?
- Что потребуется для интеграции данных
источника в поток загрузки?
- Какова технология хранения данных в
источнике?
- Насколько эффективно может
осуществляться доступ к источнику?
На
основе выполненного анализа принимаются следующие архитектурные решения:
1.
Определяются состав, содержание и
источники потоков данных, которые будут поступать из источников в хранилище.
2.
Определяются преобразования, которые
должны быть выполнены над данными при загрузке, а также периодичность загрузки
данных в хранилище.
3.
При необходимости проектируются
структуры оперативного склада данных и транзитных файлов.
4.
Выявляются данные, которые отсутствуют
в источниках информационного хранилища. Для таких данных, как правило,
проектируются процедуры и регламенты ручного ввода.
Общая
структура репозитария хранилища является своего рода отражением
главной цели его построения, а именно максимально полно и быстро удовлетворить
потребности пользователей в той или иной информации.
В
зависимости от потребностей пользователей в информации можно выделить следующие
ее основные типы:
- Персональную
информацию – эта информация, используемая
пользователями со строго определенными обязанностями и информационными
потребностями. Обычно требует большой предварительной обработки, или,
другими словами, имеет высокий уровень агрегации. Чаще всего храниться в
МБД.
- Информацию
по бизнес-темам – информация, относящаяся к
определенной тематике, например, как финансовая деятельность организации.
Для организаций имеющих близкие функциональные и организационные
структуры, ее можно определить как информацию для подразделения (например,
для финансовой службы). Имеет более широкий спектр, как в предметных
областях, так и вовремени, но вместе с тем напрямую используется реже, чем
персонализированная информация. Обычно храниться в смешанных структурах:
МБД и реляционных таблицах.
- Детальные
данные – самая подробная информация,
доступная в хранилище данных. Обычными пользователями применяется весьма
редко, только в случае необходимости подробного уточнения информации.
Обычно является полем деятельности аналитиков по добыче знаний (или поиску
скрытых зависимостей в больших объемах информации). Обычно храниться в
реляционных структурах.
- Устаревшие детальные данные
– это, по сути, тот же самый низкий уровень агрегирования, что и у текущих
детальных данных, - выделяются в особый тип по следующей причине. С одной
стороны, старые детальные данные часто требуют больших ресурсов для
хранения, а с другой – они со временем, например, через несколько лет,
необходимы очень редко. Решением в данном случае является использование
более дешевых и емких способов хранения, например лент или библиотек.
3. Компонентная архитектура.
Система
на самом верхнем уровне состоит, как правило, из двух видов ПО: общего и
специального.
К общему ПО относятся:
ПО промежуточного слоя,
которое обеспечивает сетевой доступ к приложениям и БД. Сюда относятся сетевые
и коммуникационные протоколы, драйверы, системы обмена сообщениями и пр.
ПО загрузки и предварительной обработки
данных. Этот уровень включает в себя набор
средств для загрузки данных из OLTP-систем и внешних источников Проектируется,
как правило, в сочетании с дополнительной обработкой: проверкой данных на
чистоту, консолидацией, форматированием, фильтрацией и пр.
Серверное ПО.
Представляет собой ядро всей системы. Оно включает в себя:
- Серверы реляционных БД,
- Серверы МБД,
- Серверы приложений (поисковые,
аналитической обработки, добычи знаний и др.).
Специальное ПО
представляет собой совокупность программ, разрабатываемых при создании Систем
Поддержки Принятия Решений (СППР). Они объединяются в следующие подсистемы:
1.
Подсистему загрузки данных,
2.
Подсистему обработки запросов и представления данных,
3.
Подсистему администрирования.
В этой части должны быть спроектированы
модули, составляющие подсистему, и алгоритмы отдельных процедур, входящих в их
состав.
4. Техническая архитектура.
Серверное
ПО работает под управлением серверов приложений и серверов БД.
Клиентское
ПО, устанавливается на ПК конечных пользователей. В последние
годы наметилось стремительное внедрение технологии «тонкого» клиента, при
которой на ПК пользователя находится лишь Web-браузер, а вся функциональность
клиентского ПО загружается с сервера приложений в виде JavaScript-
программ или апплетов. Техническая архитектура во многом зависит от масштабов и
требований, предъявляемых к ее производительности и надежности. В зависимости
от этого серверные компоненты системы могут располагаться на одном компьютере
или на нескольких. Сегменты хранилища и витрины данных в больших системах могут
располагаться на нескольких компьютерах.
3.
РЕАЛИЗАЦИЯ.
Данная
фаза проекта непосредственно связана с разработкой и тестированием компонентов
информационного и специального ПО системы в соответствии с разработанной на
этапе проектирования архитектурой.
К
основным результатам работы на этом этапе следует отнести:
·
Непосредственно саму систему в виде
общего и специального ПО, баз данных.
·
План внедрения системы, который должен
определять все работы по внедрению системы у заказчика, включая упаковку
системы, доставку ее заказчику, инсталляцию системы на технических средствах
заказчика, тестирование и доработку.
·
Набор тестов, которые должны быть
выполнены после установки системы у заказчика.
·
Пользовательскую документацию и учебные
материалы для пользователей системы.
4.
ВНЕДРЕНИЕ.
Данная
фаза состоит в выполнении работ, предусмотренных планом внедрения, который был
разработан на предыдущей фазе.
На
стадии развертывания осуществляются монтаж и установка системы и отдельных ее
компонентов у заказчика. Осуществляется первоначальная загрузка хранилища
необходимыми данными, выполняется опытная эксплуатация системы. Кроме того, на
стадии развертывания осуществляется обучение пользователей и сотрудников службы
технической поддержки. Окончанием данного этапа считается момент перехода к
производственной эксплуатации хранилища.
3.
СТРУКТУРА ХРАНИЛИЩА ДАННЫХ.
3.1.
Выбор метода реализации хранилищ данных.
Способы доступа к источникам данных
определяют архитектуру аналитических платформ.
В соответствии с используемыми
способами все аналитические платформы
делятся на две группы.
Платформы первой группы
ориентированы на работу с выделенными источниками данных - хранилищами и
витринами данных, которые специально сформированы для аналитической обработки,
что выражается и в особых структурах и моделях данных этих источников. В
настоящее время наибольшее признание в качестве модели данных для анализа
данных получила многомерная модель, которая может быть реализована и средствами
реляционных СУБД, и средствами многомерных (OLAP) СУБД. Эффективность и удобство
выполнения анализа при использовании последних значительно выше, чем при
применении реляционных СУБД, поэтому OLAP-серверы является ядром аналитических
платформ первой группы. К этой группе относятся аналитические платформы Microsoft,
Oracle Business Intelligence Suite Standard Edition
и др.
Платформы второй группы разработаны
для работы с более широким кругом источников, в который входят:
-
хранилища и витрин данных
(реляционные и многомерные);
- «обычные» базы данных, создаваемые транзакционными (класса OLTP) системами;
- возможно, другие
источники данных (такие, как XML-файлы, «плоские файлы», файлы MS Excel и др.)
Можно сказать, что эти платформы в принципе «равноудалены» от различных источников данных. В состав платформ второй группы не входят OLAP-серверы и другие средства непосредственного доступа к источникам данных. Для доступа к данным в этих платформах используются в основном стандартные интерфейсы к соответствующим серверам. Кроме того, в некоторых платформах используются и «родные» для конкретных источников интерфейсы.
В состав хранилища данных, как правило,
входит:
– виртуальное хранилище данных;
– витрины данных;
– глобальное хранилище данных;
– многоуровневая архитектура хранилища
данных.
Виртуальное хранилище данных.
В его основе лежит репозиторий метаданных, который описывается источниками
информации (БД транзакционных систем,
внешние файлы и др.), SQL-запросами для их считывания и процедурами обработки и
предоставления информации. Непосредственный доступ к виртуальным хранилищам
данных обеспечивает программное обеспечение промежуточного слоя. В этом случае
избыточность данных нулевая. Конечные
пользователи фактически работают с транзакционными системами напрямую со всеми вытекающими отсюда
плюсами (доступ к не агрегированным
данным в реальном времени) и минусами (интенсивный сетевой трафик, снижение
производительности OLTP-систем и реальная угроза их работоспособности
вследствие неудачных действий
пользователей-аналитиков).
Витрина данных. Витрина
данных (Data Mart) – это облегченный вариант хранилища данных, содержащий
только тематически объединенные данные.
Целевая база данных максимально приближена к
конечному пользователю и
может содержать тематически ориентированные агрегатные данные. Витрина
данных существенно меньше по объему, чем хранилище данных, поэтому его
реализации не требуется мощная вычислительная техника.
Глобальное хранилище данных.
В последнее время все более популярной становится идея совместить концепции
хранилища и витрины данных в одной
реализации и использовать хранилище данных в качестве единственного источника интегрированных данных
для всех витрин данных. Тогда естественной
становится следующая ТРЕХУРОВНЕВАЯ АРХИТЕКТУРА СИСТЕМЫ.
На первом уровне архитектуры реализуется
корпоративное хранилище данных на основе одной из развитых современных
реляционных СУБД (примером такой системы является Microsoft
SQL Server 2014). Это хранилище состоит,
в основном, из детализированных данных. Реляционные СУБД обеспечивают эффективное
хранение и управление данными очень
большого объема, но не слишком хорошо соответствуют потребностям OLAP-систем, в частности, в связи
с требованием многомерного представления
данных.
На втором уровне архитектуры поддерживаются
витрины данных на основе многомерной системы управления базами данных.
Такие СУБД почти идеально подходят для
целей разработки OLAP-систем, но пока не позволяют хранить сверхбольшие объемы данных. В данном
случае это и не требуется, поскольку речь идет о витринах данных. Необходимо
заметить, что витрина данных не
обязательно должна быть полностью сформирована. Она может содержать ссылки на
хранилище данных и добирать оттуда информацию
по мере поступления запросов. Конечно, это несколько увеличивает время отклика, но зато снимает
проблему ограниченного объема
многомерной базы данных.
ПРИМЕРЫ СУБД.
- Oracle
Database или Oracle RDBMS —
объектно-реляционная система управления базами данных компании Oracle.
Направление
хранилищ данных и аналитических систем является сегодня для компании Oracle одним из самых приоритетных. Будучи
поставщиком полного технологического решения в данной области, Oracle выпускает новые продукты и постоянно
совершенствует существующие.
В
общем виде, технология функционирования любой корпоративной
информационно-аналитической системы состоит в следующем. Данные поступают из
различных внутренних транзакционных систем, от подчиненных структур, от внешних
организаций в соответствии с установленным регламентом, формами и макетами
отчетности. Вся эта информация проверяется, согласуется, преобразуется и
помещается в хранилище и витрины данных. После этого пользователи с помощью специализированных
инструментальных средств получают необходимую им информацию для построения
различных табличных и графических представлений, прогнозирования, моделирования
и выполнения других аналитических задач.
В
соответствии с этим основными функциями информационно-аналитической системы
являются:
1)
извлечение
данных из различных источников, их преобразование и загрузка в хранилище;
2)
хранение
данных;
3)
анализ
данных, включая регламентированные отчеты, произвольные запросы, многомерный
анализ (OLAP) и извлечение знаний (data mining).
Обычно
для выполнения этих функций используются различные продукты, что приводит к
усложненной архитектуре системы, необходимости интегрировать разнородные
инструментальные среды, дополнительным затратам на администрирование, проблемам
согласования данных и метаданных на различных серверах.
Корпорация
Oracle предлагает
новый подход к созданию аналитических систем – единую и функционально полную
платформу для решения всех перечисленных задач.
Основой
решения является система управления базами данных Oracle Database, с помощью которой можно не только
надежно хранить огромные объемы аналитической информации, но и эффективно
выполнять процедуры извлечения данных из разнородных источников, согласовывать,
агрегировать и преобразовывать эти данные в аналитическую информацию, загружать
ее в хранилище. Кроме того, средствами этого же продукта поддерживаются
различные методы анализа данных, включая многомерный анализ, прогнозирование,
поиск закономерностей. Все эти функции реализуются специальными компонентами Oracle Database.
В 2013 году вышла версия Oracle Database 12c (12.1.0.1),
основное новшество — поддержка подключаемых баз данных (англ. pluggable
database), обеспечивающая свойства мультиарендности и живой миграции баз данных,
суффикс «c»
в названии обозначает англ. cloud (облако).
Oracle Database 12c предлагает новую мультиарендную
архитектуру, которая упрощает быструю консолидацию большого числа баз данных и
управление ими как облачной службой. Oracle
Database 12c также предоставляет возможности обработки данных в памяти и
беспрецедентную эффективность аналитики. Дополнительные инновации,
реализованные в базах данных, обеспечивают эффективность, производительность,
безопасность и доступность совершенно нового уровня.
Oracle Database 12c поставляется в трех выпусках,
соответствующих любым бизнес-нуждам и бюджету: Enterprise Edition, Standard
Edition и Standard Edition One.
Более подробную информацию о СУБД Oracle
Database можно найти на официальном сайте разработчика по адресу: http://www.oracle.com/ru/database/overview/index.html.
- Microsoft
SQL Server – система управления реляционными базами
данных (СУРБД), разработанная корпорацией Microsoft.
В 2014 году выпущен релиз Microsoft SQL Server 2014. По данным
Gartner, SQL Server 2014 занимает ведущее место среди разработчиков. В продукте
Microsoft SQL Server используется общий
набор средств для развертывания баз данных и управления ими как локально, так и
в «облаке».
Более подробную информацию о СУРБД Microsoft
SQL Server 2014 можно найти на официальном сайте разработчика по адресу: http://www.microsoft.com/ru-ru/server-cloud/products/sql-server/Overview.aspx.

На третьем уровне архитектуры находятся
клиентские рабочие места конечных пользователей, на которых устанавливаются
средства оперативного анализа данных.
На рисунке 1 изображены потоки данных в
информационной системе (ИС) для большой
организации, имеющей самостоятельные, часто
удаленные подразделения.
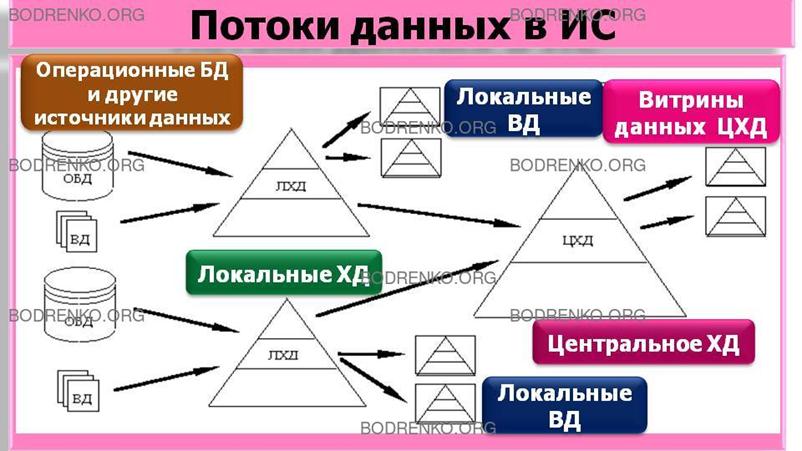
Рисунок
1. Потоки данных в ИС.
В такой ИС данные, попадающие в
хранилище данных, не используются напрямую системами представления и анализа.
Эти системы получают данные из
специально сформированных витрин данных.
Введение витрин данных позволяет
получить несколько важных преимуществ:
- конечный пользователь работает только
с теми данными, которые ему нужны;
– повышается безопасность доступа к данным;
– структура данных отражает требования
конечного пользователя;
– упрощается проектирование данных;
– снижается нагрузка на основное
хранилище данных.
Для больших организаций технология
хранилища данных реализуется в
иерархической схеме. Для хранилища данных верхнего уровня хранилище данных
уровнем ниже являются таким же источником данных, как и операционные базы данных (ОБД). ОБД
является основным, но не единственным
источником информации. Это связано с тем, что часть информации (иногда даже существенная)
хранятся в форматах, отличных от
принятых в БД. Среди таких форматов самым распространенным является текстовый файл, а средством доступа –
файловая операционная система. Эти
источники данных называются внешними данными.
Хранилища данных обладают рядом свойств
(предметная ориентация; интегрированность данных; инвариантность во времени;
неразрушаемость – стабильность информации; интеграция; минимизация избыточности
информации). Подробно свойства ХД мы рассмотрели на лекции 1 «Технологии хранилища
данных».
3.2. Моделирование
хранилищ данных.
Традиционные подходы
моделирования хранилищ данных основываются, как правило, на использовании
временных отметок создания записей и их
модификации.
Наиболее известны следующие три основных способа моделирования времени в хранилищах данных:

1. Модель снимков данных.
Снимок данных – это представление
данных в определенный момент времени. Данная модель характерна для оперативных
систем (OLTP). Обновления данных носят деструктивный характер, т. е. предыдущие
значения атрибутов замещаются новыми значениями (рисунок 2).
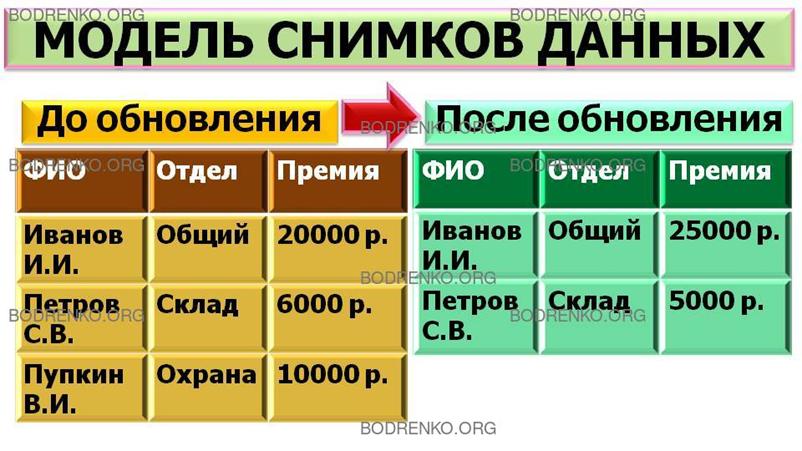
Рисунок
2. Модель снимков данных.
Модель снимков данных имеет достаточно
ограниченный круг применения в хранилищах данных, поскольку не обеспечивает
хранения истории изменений.
2. Событийная модель.
Событийная модель (рисунок 3) используется
для моделирования событий (данных), возникающих в определенные моменты времени.
Данная модель подходит для моделирования транзакций, таких как: продажи, финансовые транзакции, складские
операции и т. д.
Счет
Клиент Сумма Дата
1000
Школа-Стиль 55
000 р. 08.25.2015
1001 Планета-Инфо 4 500 р. 08.25.2015
1002 ТехноДизайн 12 000 р. 08.25.2015

Рисунок
3. Событийная модель.
3. Статусная модель.
Статусная модель используется для
моделирования состояния объектов во
времени. Она подходит для представления данных, имеющий нетранзакционный характер.
Существует три способа моделирования
изменяющихся во времени статусов:
а) непрерывная модель – для
хранения промежутков времени используется одно поле даты. Дата начала
следующего периода совпадает с датой
окончания предыдущего;
б) начало и конец – для хранения
промежутков времени используется два поля – дата начала и дата окончания
периода действия статуса;
в) начало и длительность – для
хранения промежутков времени используется одно поле даты (дата начала) и поле
длительности периода.
Большее распространение при создании
статусных моделей получил способ «начало и конец» (рисунок 4).
ФИО Отдел Зарплата Дата начала Дата окончания
Иванов И.И. Общий 30 000 р. 01.01.2015 08.25.2015
Петров С.В. Склад
14 500 р. 01.01.2015 08.25.2015
Пупкин В.И. Охрана 17 500 р. 01.01.2015 08.25.2015
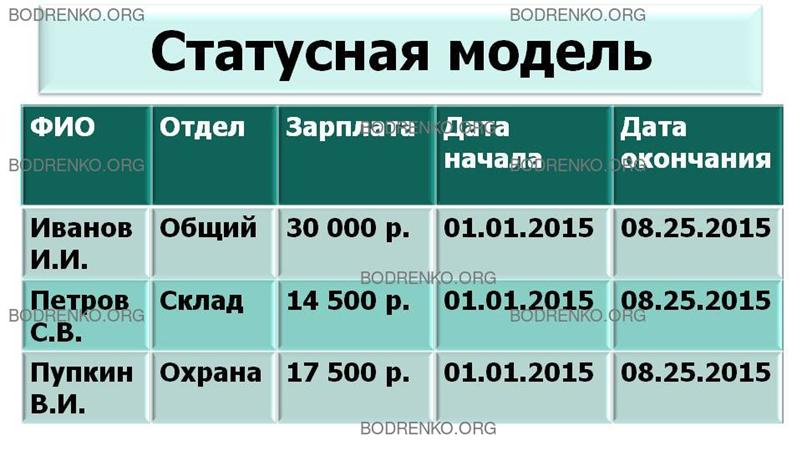
Рисунок
4. Статусная модель.
Статусная и событийная модели являются
взаимно дополняющими.
Путем преобразований из одной можно получить
другую. Например, зная остаток на счете
на определенный момент и историю транзакций в событийной модели, можно восстановить все
статусы счета (остатки на счете) в
периоды между транзакциями. И наоборот, имея статусную модель остатков на счете, можно вычислить
события (т. е. транзакции), которые происходили со счетом в начале (конце)
каждого периода.
3.3. Моделирование
витрин данных.
Приемы моделирования витрин данных
отличаются от приемов моделирования
хранилищ данных в силу различных требований к структурам данных. Если основной задачей
хранилища данных является хранение
консолидированной исторической информации, то витрина данных строится с учетом требований по доступу
к данным и представления информации. Как
правило, для моделирования витрин данных используются типы модели под названием: схема «звезда» и схема
«снежинка».
- Схема
«звезда».
Схема «звезда» – популярный тип модели
данных для витрин данных. Данная модель характеризуется наличием таблицы
фактов, окруженной связанными с ней
таблицами измерений (размерностей). Запросы к такой структуре включают простые объединения таблицы фактов с
каждой из таблиц размерностей (рисунок 5).
Данная модель характеризуется высокой производительностью запросов.
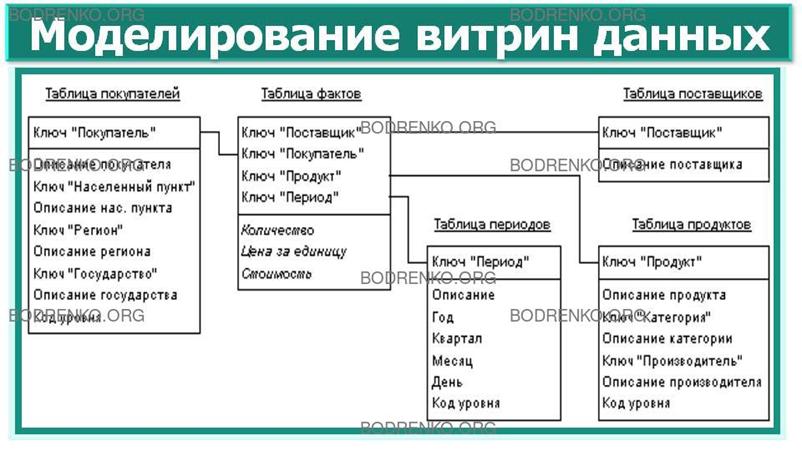
Рисунок
5. Схема «звезда».
Схема «звезда» имеет следующие
компоненты:
Измерение (размерность). В технологии многомерного моделирования
размерность – это аспект, в разрезе
которого можно получать, фильтровать, группировать и отображать информацию о фактах.
Типичные измерения (размерности),
встречающиеся практически в любой модели:
– покупатель,
– продукт,
– время (период),
– география,
– сотрудник.
Измерение (размерность), как правило,
имеет многоуровневую иерархическую структуру. Например, измерение «время» может
иметь следующую структуру: год, квартал,
месяц, день.
Факты.
Факты – это величины, обычно числовые,
хранящиеся в таблице фактов и являющиеся
предметом анализа. Примеры фактов: объем операций, количество проданных единиц товара и
т. д.
Можно выделить три типа фактов (см.:
лекция 2 «Многомерные хранилища данных»):
а) АДДИТИВНЫЕ ФАКТЫ. Аддитивность
определяет возможность суммирования факта вдоль определенной размерности.
Аддитивные факты можно суммировать и
группировать вдоль всех размерностей на любых уровнях иерархии;
б) ПОЛУАДДИТИВНЫЕ ФАКТЫ. Полуаддитивный
факт – это факт, который можно
суммировать вдоль определённых размерностей, и нельзя – вдоль других. Примером может служить
остаток на счете (или остаток товара на
складе). Данную величину нельзя суммировать вдоль размерности время. Однако
сумма остатков по счетам является часто встречаемой величиной для анализа;
в) НЕАДДИТИВНЫЕ ФАКТЫ. Неаддитивные
факты вообще нельзя суммировать. Пример
неаддитивного факта – отношение (например, выраженное в процентах).
ТАБЛИЦЫ ПОКРЫТИЯ.
Таблицы покрытия используются с целью
моделирования сочетания измерений (размерностей), для которых отсутствуют
факты.
Например, нужно найти количество категорий продуктов, которые
сегодня ни разу не продавались. Таблица фактов продаж не может ответить на
данный вопрос, поскольку она регистрирует только факты продаж. Для того чтобы
модель позволяла отвечать на подобные
вопросы, необходима дополнительная таблица фактов (которая, по сути дела, не содержит
фактов) и которая и называется таблицей
покрытия.
- Схема
«снежинка».
Данная схема (рисунок 6) используется
для нормализации схемы «звезда».
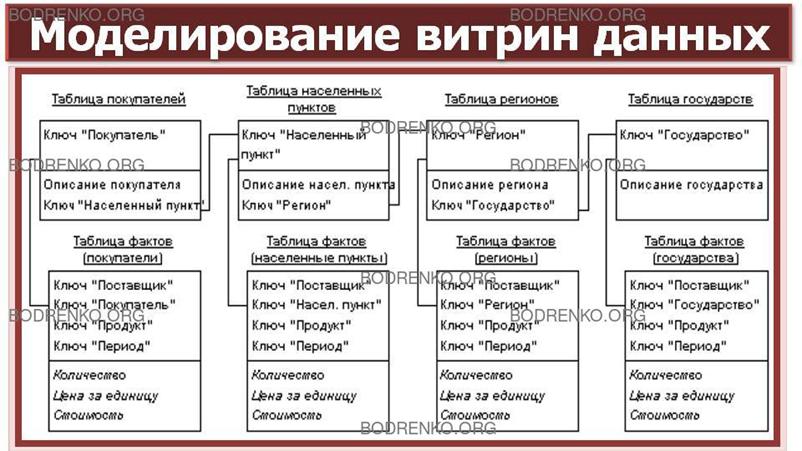
Рисунок
6. Схема «снежинка».
Такая схема сокращает избыточность в
таблицах измерений (размерностей). Основным достоинством схемы «снежинка»
является возможность создания таблицы
фактов с разным уровнем детализации. Например, фактические данные на уровне дня, а плановые –
на уровне месяца. Вследствие чего возрастает скорость выполнения запросов в
структуре размерностей. Например, запросы вида «выбрать все строки из таблицы
размерности на определенном уровне».
3.4.
Способы аналитической обработки данных.
3.4.
Для того чтобы существующие хранилища
данных способствовали принятию
управленческих решений, информация должна быть представлена аналитику в нужной форме, т. е.
он должен иметь развитые инструменты
доступа к данным хранилища и их обработки.
Очень часто информационно-аналитические
системы, создаваемые в расчете на
непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в
применении, но жестко ограничены в
функциональности. Такие статические системы называются Информационными системами руководителя
(ИСР), или Executive Information Systems (EIS). Они содержат в
себе множества запросов и, будучи достаточными для повседневного обзора,
неспособны ответить на все вопросы
которые могут возникнуть при принятии решений.
Результатом работы такой системы, как
правило, являются многостраничные
отчеты, после тщательного изучения, которых у аналитика появляется новая серия вопросов.
Однако каждый новый запрос, непредусмотренный при проектировании такой
системы, должен быть сначала формально описан, закодирован программистом и
только затем выполнен. Время ожидания в
таком случае может составлять часы и дни, что не всегда приемлемо.
Системы поддержки принятия решений
(СППР).
Системы поддержки принятия решений
(СППР) – это класс ИС, предназначенных для решения задач поддержки всех стадий
принятия решений в слабо структурируемых
и неструктурируемых предметных областях непосредственными пользователями в
процессе аналитического моделирования. Специфика СППР заключается, прежде
всего, в предоставлении
пользователю возможности получения нерегламентированных отчетов, различных
методов анализа данных, что
позволяет эффективнее решать
слабо структурируемые и неструктурируемые задачи, вырабатывать
специфические, нетиповые решения. Для решения подробного рода задач
пользователю, как правило, требуется
дополнительная уникальная и, зачастую, разовая информация из корпоративного
информационного хранилища. Поэтому, в отличие от традиционных отчетных
ИС, осуществляющих предоставление пользователю регламентной информации, СППР,
как правило, обладают мощными механизмами
интерактивного поиска, обобщения и анализа информации на основе нерегламентированных
запросов.
Алгоритмы
СППР.
Полная структура информационно-аналитической системы,
построенной на основе хранилища данных, показана на рисунке 7.
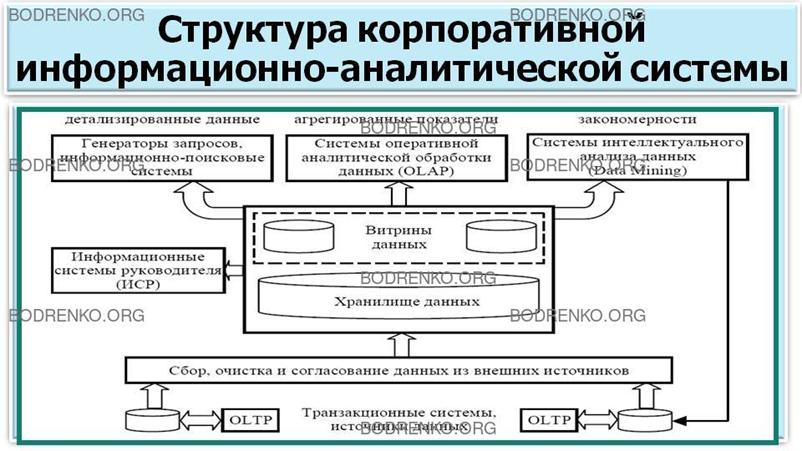
Рисунок
7. Структура корпоративной информационно-аналитической системы.
Важнейшей целью СППР является, в первую
очередь, обеспечение пользователя
технологией формирования информации. Так как процесс формирования нетиповых решений является трудно
формализуемым, то вместо модулей,
отражающих регламентную информацию, в составе СППР используется набор средств, каждое из
которых может быть использовано
пользователем для получения и анализа информации. СППР ориентированы не на процесс, а на набор
возможностей, предоставляемых пользователю.
В статических СППР
конечному пользователю предоставляется не поддержка однозначно описанного процесса
обработки данных, а набор возможностей,
не зависящих от процесса. Поэтому использование статических СППР невозможно без глубоких знаний пользователем предметной
области.
Динамические СППР,
напротив, ориентированы на обработку нерегламентированных запросов аналитиков к
данным. Работа аналитиков с этими
системами заключается в интерактивной последовательности формирования запросов и изучения их
результатов.
Поддержка принятия управленческих
решений на основе накопленных данных
может выполняться с помощью трех алгоритмов (рисунок 7):
1. Генерация запросов, с
использованием детализированных данных.
Используется в большинстве систем, нацеленных
на поиск информации. Как правило,
реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом
языка манипулирования реляционными
данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного
пользователя в задачах поиска
детализированной информации, могут использоваться в качестве надстроек, как над отдельными базами данных
транзакционных систем, так и над общим хранилищем данных.
2. Оперативная аналитическая обработка
данных, с использованием агрегированных показателей.
Позволяют реализовать комплексный
взгляд на собранную в хранилище данных информацию, обобщение и агрегацию, гиперкубическое представление и многомерный
анализ данных. Здесь могут
использоваться либо специальные многомерные СУБД, либо реляционные технологии. Во втором случае
заранее агрегированные данные могут
собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в
процессе сканирования детализированных
таблиц реляционной БД.
3. Интеллектуальный анализ
данных, с использованием закономерностей.
Главными задачами интеллектуального
анализа данных являются поиск
функциональных и логических закономерностей в накопленной информации, построение моделей и правил,
объясняющие найденные аномалии и/или прогнозирующие развитие некоторых процессов.
3.5.
Варианты архитектуры СППР.
На сегодняшний день известно несколько
способов построения СППР. Среди них можно выделить следующие четыре наиболее
популярные типы архитектур систем поддержки принятия решений.
I.
Функциональная СППР.
II. СППР с использованием независимых
витрин данных.
III. СППР на основе двухуровневого
хранилища данных.
IV. СППР на основе трехуровневого
хранилища данных.

I. Функциональная СППР.
Функциональная СППР (рисунок 8)
является наиболее простой с архитектурной точки зрения. Каждый
пользователь (аналитик) использует данные из любого доступного источника данных.
Такие системы часто встречаются на
практике, в особенности, в организациях с недостаточно развитой информационной инфраструктурой.
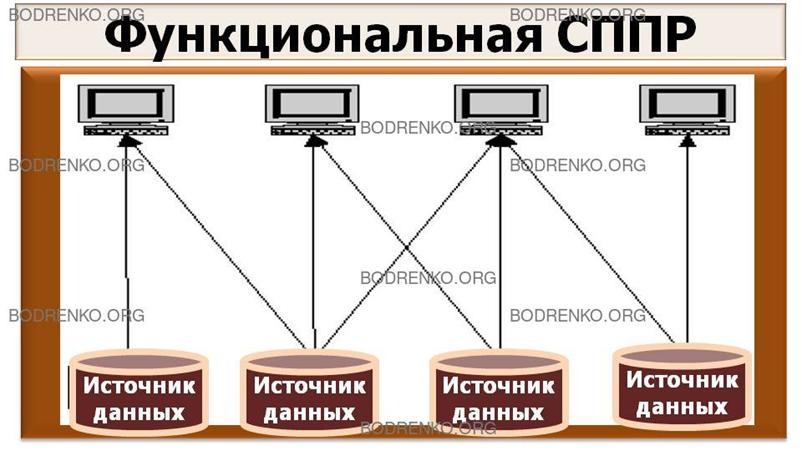
Рисунок
8. Функциональная СППР.
К преимуществам функциональной СППР
можно отнести следующие:
– быстрое внедрение за счет отсутствия
этапа перегрузки данных в специализированную систему;
– минимальные затраты за счет использования
одной платформы.
Недостатками функциональной СППР
являются:
– оперативные системы характеризуются
очень низким качеством данных с точки зрения их роли в поддержке принятия
стратегических решений. В силу отсутствия этапа очистки данных данные функциональной
СППР, как правило, обладают невысоким качеством;
– большая нагрузка на оперативную
систему. Сложные запросы могут привести к остановке работы оперативной системы.
II. СППР с использованием независимых
витрин данных.
В СППР с использованием независимых
витрин данных (рисунок 9) в зависимости от предметной области анализа
формируются витрины данных, куда
поступает информация из внешних источников данных. Пользователи (аналитики) для решения
конкретных вопросов работают только с
необходимыми витринами данных. Как правило, отдельная витрина данных
формируется для отдельного подразделения. Такие СППР обычно встречаются в
крупных организациях с большим
количеством независимых подразделений, зачастую имеющих свои собственные отделы
информационных технологий.
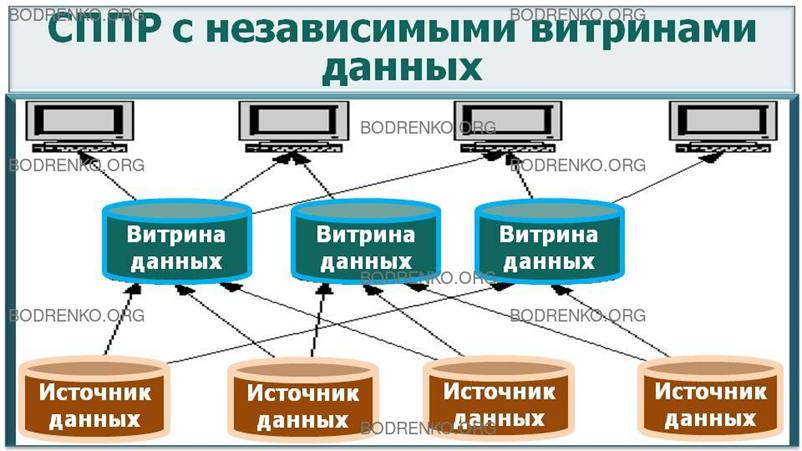
Рисунок
9. СППР с независимыми витринами данных.
Преимущества СППР с независимыми
витринами данных:
– высокая скорость внедрения киосков
(витрин) данных;
– проектирование витрины для
конкретного ряда вопросов;
– повышение производительности СППР в
связи с оптимизацией данных для определенных групп пользователей.
Недостатками СППР с независимыми
витринами данных являются:
– многократное хранение данные в различных
витринах данных. Это приводит к дублированию данных и, как следствие, к
увеличению расходов на хранение и потенциальным проблемам, связанным с необходимостью
поддержания непротиворечивости данных;
– потенциально очень сложный процесс
наполнения витрин данных при большом количестве источников данных;
– данные не консолидируются на уровне
предприятия, что способствует отсутствию единой картины бизнеса.
III. СППР на основе двухуровневого
хранилища данных.
В СППР на основе двухуровневого ХД
(рисунок 10) от всех доступных внешних источников информация поступает в ХД,
где она проходит обработку, необходимую
для эффективного функционирования ХД (парсинг, нормализация и т. д.). Для поддержки
архитектуры двухуровневого ХД необходимо
согласование всех определений и процессов преобразования данных в рамках всей
организации.

Рисунок
10. СППР на основе двухуровневого ХД.
Преимуществами СППР с двухуровневым ХД
являются:
– хранение данных в единственном
экземпляре;
– минимальные затраты на хранение
данных;
– отсутствие проблем, связанных с
синхронизацией нескольких копий данных;
– консолидация данных на уровне предприятия,
что позволяет иметь единую картину бизнеса.
К недостаткам можно отнести:
– данные не структурируются для поддержки
потребностей отдельных пользователей или групп пользователей;
– возможны проблемы с
производительностью системы;
– возможны трудности с разграничением
прав пользователей на доступ к данным.
IV. СППР на основе трехуровневого
хранилища данных.
Трехуровневое ХД (рисунок 11)
представляет собой единый централизованный источник информации. Витрины данных
представляют подмножества данных из ХД,
организованные для решения задач отдельных подразделений компании. Конечные
пользователи (аналитики) имеют
возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также
для получения более полной картины
состояния бизнеса.
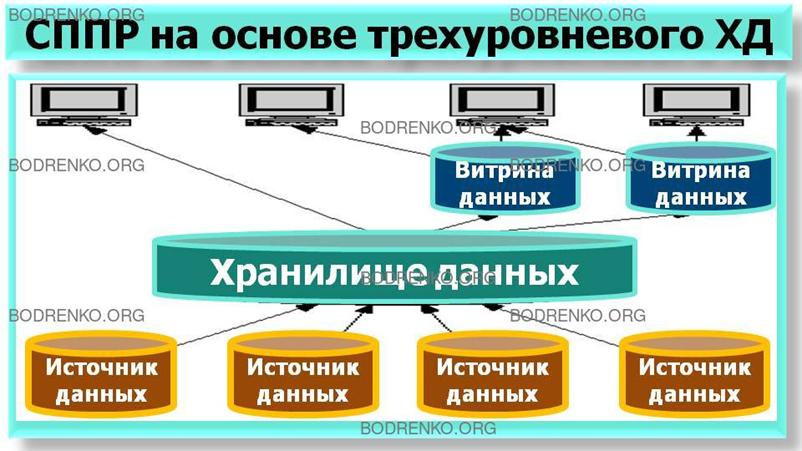
Рисунок
11. СППР на основе трехуровневого хранилища данных.
Преимуществами СППР с трехуровневым ХД
являются:
– упрощение процедуры создания и
наполнения витрин данных. Это связано с тем, что наполнение происходит из
единого стандартизованного надежного
источника очищенных нормализованных данных;
– синхронизация и совместимость витрины
данных с корпоративным представлением.
Существует возможность сравнительно легкого расширения хранилища и добавления новых витрин
данных;
– гарантированная производительность.
Недостатками таких СППР являются:
– существование избыточности данных,
приводящих к росту требований на хранение данных;
– требование согласованности принятых
архитектурных решений с различными корпоративными требованиями (например,
скорость внедрения иногда конкурирует с архитектурными решениями).
СПИСОК
РЕКОМЕНДОВАННОЙ ЛИТЕРАТУРЫ.
[1] Барсегян А. А., Куприянов М. С. , Степаненко В. В., Холод И. И. Методы и модели анализа данных: OLAP и Data Mining. – СПб.: БХВ-Петербург, 2004. - 336 с.
[2] Борисов
Д.Н. Корпоративные информационные
системы. Учебно-методическое пособие для вузов. Издательско-полиграфический
центр Воронежского государственного университета. Воронеж, 2007. – 99 с.

[3] Спирли Э. Корпоративные хранилища данных.
Планирование, разработка, реализация. Том 1. – М.: Издательский дом «Вильямс»,
2001.
[4] Туманов В.Е. Проектирование хранилищ данных для систем бизнес-аналитики:
учебное пособие. – М.:Интернет-Университет Информационных технологий: Бином.
Лаборатория знаний, 2010. – 615 с.
[5] Фоменко Е.Ю. Хранилища данных. Анализ данных: Курс
лекций. - М.: Ф-т ВМиК МГУ им. М.В. Ломоносова, 2007.
