Хранилища данных. Аналитическая обработка информации при помощи хранилища данных. OLAP-системы: история развития и характеристики. Тест FASMI. Архитектура OLAP-систем. Технологии хранилища данных. Многомерные хранилища данных. Аналитическая обработка информации при помощи хранилища данных.
Решение задач и выполнение научно-исследовательских разработок: Отправьте запрос сейчас: irina@bodrenko.org
математика, IT, информатика, программирование, статистика, биостатистика, экономика, психология
Пришлите по e-mail: irina@bodrenko.org описание вашего задания, срок выполнения, стоимость
Хранилища данных
Лекция 3
Тема лекции: «Аналитическая
обработка информации при помощи
хранилища данных»

1. OLAP-системы:
история развития и характеристики.
2. Тест FASMI.
3. Архитектура
OLAP-систем.

- OLAP- СИСТЕМЫ: ИСТОРИЯ РАЗВИТИЯ И
ХАРАКТЕРИСТИКИ.
1.1.
Определение OLAP-систем.
С
концепцией многомерного анализа данных тесно связывают оперативный анализ,
который выполняется средствами OLAP-систем.
OLAP (On-Line Analytical
Processing) – технология оперативной аналитической обработки данных, использующая
методы и средства для сбора, хранения и анализа многомерных данных в целях
поддержки процессов принятия решений.
Основное
назначение OLAP-систем – поддержка аналитической деятельности, произвольных
(часто используется термин ad-hoc) запросов пользователей-аналитиков.
Цель
OLAP-анализа – проверка возникающих
гипотез.
Идея
обработки многомерных данных восходит к 1962 г., когда Кен Айверсон опубликовал
свою работу «Язык программирования» (A
Programming Language, APL). [см.: Iverson K.E.
A Programming Language. New York: Wiley, 1962].
APL
— это математически определенный язык с многомерными переменными и изящными, но
довольно абстрактными операторами. В 1970-е и 1980-е годы он активно
использовался во многих деловых приложениях, функционально схожих с
современными OLAP-системами.
В
1970 г. впервые появился прикладной программный продукт для многомерного
анализа данных – Express (позднее приобретённый корпорацией Oracle и
преобразованный в OLAP-опцию для Oracle Database), Определенные модификации данного
продукта широко используются в современных OLAP-приложениях, однако изначальные
концепции 1970-х остались далеко позади.
В 1992 году компания Arbor Software запатентовала под
наименованием Essbase метод и вычислительный аппарат хранения и
получения многомерных данных на компьютере.
Таким
образом, в 1992 г. был выпущен Essbase
- первый OLAP-продукт, завоевавший большую долю рынка («первая коммерчески успешная
OLAP-система»).
У
истоков технологии OLAP стоит основоположник реляционного подхода Эдгар Кодд.
В
1993 году, при поддержке компании Arbor Software, вышла в свет статья Э. Кодда,
где впервые было дано формальное определение OLAP-технологии. Эта работа
получила большой резонанс и привлекла внимание к возможностям многомерного
анализа. В статье были описаны 12 правил
OLAP, к которым чуть позже (в 1995 г.) добавились еще несколько. Все эти
правила были разделены на четыре группы и названы «характеристиками»
(features).
1.2. Двенадцать правил OLAP.
В
1993 году Кодд опубликовал статью под названием «OLAP для
пользователей-аналитиков: каким он должен быть». В данной работе изложены
основные концепции оперативной аналитической обработки и определены следующие
12 требований, которым должны удовлетворять продукты, позволяющие выполнять
оперативную аналитическую обработку.
Перечислим
12 правил, изложенных Коддом и
определяющих OLAP.
1.
Многомерность. OLAP-система на
концептуальном уровне должна представлять данные в виде многомерной модели, что
упрощает процессы анализа и восприятия информации.
2.
Прозрачность. OLAP-система должна скрывать от
пользователя реальную реализацию многомерной модели, способ организации,
источники, средства обработки и хранения.
3.
Доступность. OLAP-система должна предоставлять
пользователю единую, согласованную и целостную модель данных, обеспечивая
доступ к данным независимо от того, как и где они хранятся.

4.
Постоянная производительность при
разработке отчетов. Производительность OLAP-систем не должна значительно
уменьшаться при увеличении количества измерений, по которым выполняется анализ.
5.
Клиент-серверная архитектура. OLAP-система должна быть способна
работать в среде "клиент-сервер", т. к. большинство данных, которые
сегодня требуется подвергать оперативной аналитической обработке, хранятся распределенно.
Главной идеей здесь является то, что серверный компонент инструмента OLAP
должен быть достаточно интеллектуальным и позволять строить общую
концептуальную схему на основе обобщения и консолидации различных логических и
физических схем корпоративных БД для обеспечения эффекта прозрачности.
6.
Равноправие измерений. OLAP-система должна поддерживать
многомерную модель, в которой все измерения равноправны. При необходимости
дополнительные характеристики могут быть предоставлены отдельным измерениям, но
такая возможность должна быть предоставлена любому измерению.

7.
Динамическое управление разреженными
матрицами. OLAP-система должна обеспечивать оптимальную обработку
разреженных матриц. Скорость доступа должна сохраняться вне зависимости от
расположения ячеек данных и быть постоянной величиной для моделей, имеющих
разное число измерений и различную степень разреженности данных.
8.
Поддержка многопользовательского режима.
OLAP-система должна предоставлять возможность работать нескольким
пользователям совместно с одной аналитической моделью или создавать для них
различные OLAP-системы модели из единых данных. При этом возможны как чтение,
так и запись данных, поэтому система должна обеспечивать их целостность и
безопасность.
9.
Неограниченные перекрестные операции. OLAP-система должна
обеспечивать сохранение функциональных отношений, описанных с помощью
определенного формального языка между ячейками гиперкуба при выполнении любых
операций среза, вращения, консолидации или детализации. Система должна
самостоятельно (автоматически) выполнять преобразование установленных
отношений, не требуя от пользователя их переопределения.

10.
Интуитивная манипуляция данными. OLAP-система должна предоставлять способ
выполнения операций среза, вращения, консолидации и детализации над гиперкубом
без необходимости пользователю совершать множество действий с интерфейсом.
Измерения, определенные в аналитической модели, должны содержать всю
необходимую информацию для выполнения вышеуказанных операций.
11.
Гибкие возможности получения отчетов. OLAP-система
должна поддерживать различные способы визуализации данных, т. е. отчеты должны
представляться в любой возможной ориентации. Средства формирования отчетов
должны представлять синтезируемые данные или информацию, следующую из модели
данных в ее любой возможной ориентации. Это означает, что строки, столбцы или
страницы должны показывать одновременно от 0 до N измерений, где N – число измерений всей
аналитической модели. Кроме того, каждое измерение содержимого, показанное в
одной записи, колонке или странице, должно позволять показывать любое
подмножество элементов (значений), содержащихся в измерении, в любом порядке.
12.
Неограниченная размерность и число
уровней агрегации. Исследование о
возможном числе необходимых измерений, требующихся в аналитической модели,
показало, что одновременно может использоваться до 19 измерений. Отсюда
вытекает настоятельная рекомендация, чтобы аналитический инструмент мог
одновременно предоставить хотя бы 15, а предпочтительно – 20 измерений. Более того, каждое из общих
измерений не должно быть ограничено по числу определяемых
пользователем-аналитиком уровней агрегации и путей консолидации.

1.2. Дополнительные правила OLAP.
Набор
этих требований, послуживших де-факто определением OLAP, достаточно часто
вызывает различные нарекания, например, правила 1, 2, 3, 6 являются
требованиями, а правила 10, 11 — неформализованными пожеланиями. Таким образом,
перечисленные 12 требований Кодда не позволяют точно определить OLAP.
В
1995 году Кодд к приведенному перечню добавил следующие шесть правил:
13.
Пакетное извлечение против интерпретации. OLAP-система должна в равной степени
эффективно обеспечивать доступ как к собственным, так и к внешним данным.
14.
Поддержка всех моделей OLAP-анализа. OLAP-система
должна поддерживать все четыре модели анализа данных, определенные Коддом:
категориальную, толковательную, умозрительную и стереотипную.
15.
Обработка ненормализованных данных. OLAP-система
должна быть интегрирована с ненормализованными источниками данных. Модификации
данных, выполненные в среде OLAP, не должны приводить к изменениям данных,
хранимых в исходных внешних системах.

16.
Сохранение результатов OLAP: хранение их отдельно от исходных данных.
OLAP-система, работающая в режиме чтения-записи, после модификации исходных
данных должна результаты сохранять отдельно. Иными словами, обеспечивается
безопасность исходных данных.
17.
Исключение отсутствующих значений. OLAP-система,
представляя данные пользователю, должна отбрасывать все отсутствующие значения.
Другими словами, отсутствующие значения должны отличаться от нулевых значений.
18.
Обработка отсутствующих значений. OLAP-система
должна игнорировать все отсутствующие значения без учета их источника. Эта
особенность связана с 17-м правилом.

Кроме
того, Кодд разбил все 18 правил на следующие четыре группы, назвав их
особенностями. Эти группы получили названия В, S, R и D.
Основные особенности (В) включают следующие правила:
-
многомерное концептуальное представление данных (правило 1);
- интуитивное манипулирование данными (правило
10);
- доступность (правило 3);
-
пакетное извлечение против интерпретации (правило 13);
-
поддержка всех моделей OLAP-анализа (правило 14);
- архитектура «клиент-сервер» (правило 5);
-
прозрачность (правило 2);
-
многопользовательская поддержка (правило 8).
Специальные особенности (S) включают следующие правила:
-
обработка ненормализованных данных (правило 15);
- сохранение результатов OLAP: хранение их
отдельно от исходных данных (правило 16);
- исключение отсутствующих значений (правило
17);
-
обработка отсутствующих значений (правило 18).
Особенности представления отчетов (R) включают следующие правила:
- гибкость формирования отчетов (правило 11);
-
стандартная производительность отчетов (правило 4);
-
автоматическая настройка физического уровня (измененное оригинальное правило
7).
Управление измерениями (D) включают следующие правила:
-
универсальность измерений (правило 6);
-
неограниченное число измерений и уровней агрегации (правило 12);
- неограниченные операции между размерностями
(правило 9).

2. ТЕСТ FASMI.
Определенные
ранее особенности распространенны. Более известен тест FASMI (Fast of Shared
Multidimensional Information), созданный в 1995 году Найджелом Пендсом (Nigel
Pendse) и Ричардом Критом (Richard Creeth) на основе анализа правил Кодда. В
данном контексте акцент сделан на скорость обработки, многопользовательский
доступ, релевантность информации, наличие средств статистического анализа и
многомерность (т.е. представление анализируемых фактов как функций от большого
числа их характеризующих параметров).
Таким
образом, они определили OLAP следующими пятью ключевыми словами: Fast (Быстрый), Analysis (Анализ), Shared
(Разделяемой), Multidimensional (Многомерной), Information (Информации).
Изложим эти пять ключевых представлений более подробно.
FAST(Быстрый). OLAP-система должна обеспечивать выдачу большинства
ответов пользователям в пределах приблизительно 5 секунд. При этом самые
простые запросы обрабатываются в течение 1 секунды, и очень немногие более 20 секунд. Исследования показывают, что конечные пользователи
воспринимают процесс неудачным, если результаты не получены по истечении 30 секунд.
Они способны нажать комбинацию клавиш <Alt>+<Ctrl>+<Del>,
если система не предупредит их, что обработка данных требует большего времени.
Даже если система предупредит, что процесс будет длиться существенно дольше,
пользователи могут отвлечься и потерять мысль, при этом качество анализа
страдает. Такой скорости нелегко достигнуть с большим количеством данных,
особенно если требуются специальные вычисления «на лету». Для достижения данной
цели используются разные методы, включая применение аппаратных платформ с
большей производительностью.
ANALYSIS (Анализ). OLAP-система должна справляться с любым
логическим и статистическим анализом, характерным для данного приложения, и
обеспечивать его сохранение в виде, доступном для конечного пользователя. Естественно,
система должна позволять пользователю определять новые специальные вычисления
как часть анализа и формировать отчеты любым желаемым способом без
необходимости программирования. Все требуемые функциональные возможности
анализа должны обеспечиваться понятным для конечных пользователей способом.
SHARED (Разделяемой). OLAP-система должна
выполнять все требования защиты конфиденциальности (возможно, до уровня ячейки
хранения данных). Если множественный доступ для записи необходим,
обеспечивается блокировка модификаций на соответствующем уровне. Обработка
множественных модификаций должна выполняться своевременно и безопасным
способом.
MULTIDIMENSIONAL (Многомерной). OLAP-система должна
обеспечить многомерное концептуальное представление данных, включая полную
поддержку для иерархий и множественных иерархий, обеспечивающих наиболее
логичный способ анализа. Это требование не устанавливает минимальное число
измерений, которые должны быть обработаны, поскольку этот показатель зависит от
приложения. Оно также не определяет используемую технологию БД, если
пользователь действительно получает многомерное концептуальное представление
информации.
INFORMATION (Информации). OLAP-система должна
обеспечивать получение необходимой информации в условиях реального приложения.
Мощность различных систем измеряется не объемом хранимой информации, а
количеством входных данных, которые они могут обработать. В этом смысле
мощность продуктов весьма различна. Большие OLAP-системы могут оперировать по
крайней мере в 1000 раз большим количеством данных по сравнению с простыми
версиями OLAP-систем. При этом следует учитывать множество факторов, включая
дублирование данных, требуемую оперативную память, использование дискового
пространства, эксплуатационные показатели, интеграцию с информационными
хранилищами и т. п.

3.
АРХИТЕКТУРА OLAP-СИСТЕМ.
OLAP-система
включает в себя два основных компонента:
-
OLAP-сервер. Обеспечивает хранение
данных, выполнение над ними необходимых операций и формирование многомерной
модели на концептуальном уровне. В настоящее время OLAP-серверы объединяют с ХД
или ВД;
-
OLAP-клиент. Представляет
пользователю интерфейс к многомерной модели данных, обеспечивая его
возможностью удобно манипулировать данными для выполнения задач анализа.

OLAP-серверы
скрывают от конечного пользователя способ реализации многомерной модели. Они
формируют гиперкуб, с которым пользователи посредством OLAP-клиента выполняют
все необходимые манипуляции, анализируя данные. Между тем способ реализации
очень важен, т. к. от него зависят такие характеристики, как производительность
и занимаемые ресурсы.
Выделяют
три основных способа реализации:
-
MOLAP (для реализации многомерной
модели используют многомерные БД);
-
ROLAP (для реализации многомерной
модели используют реляционные БД);
-
HOLAP (для реализации многомерной
модели используют и многомерные и реляционные БД).

Кроме
перечисленных выше основных моделей OLAP-систем, часто в литературе по OLAP-системам можно
встретить аббревиатуры DOLAP и JOLAP.
DOLAP (Desktop OLAP) – настольный OLAP. Является недорогой и
простой в использовании OLAP-системой, предназначенной для локального анализа и
представления данных, которые загружаются из реляционной или многомерной БД на
машину клиента.
DOLAP является одноуровневой
технологией OLAP. В данной архитектуре OLAP можно скачать относительно
небольшие кубы данных из центральной точки (витрины или хранилища данных) и
выполнять многомерный анализ, отключившись от этого ресурса. В другом варианте
пользователь может сам создать OLAP-куб, не подключаясь к серверу.
Достоинства подхода DOLAP:
- дружественный (user friendly) подход для манипулирования данными в локальном режиме;
- высокая скорость обработки запросов;
- низкая стоимость;
- удобный инструмент для пользователей, которые не могут постоянно поддерживать соединение с хранилищем данных;
- наиболее простое развертывание продуктов из всех подходов к организации OLAP.
Недостатки подхода DOLAP:
- ограниченная функциональность;
- ограничение на объем данных.
Представители
DOLAP-систем: Cognos PowerPlay,
Brio, Crystal Decisions, Hummingbird.
Рассматривая интерфейсы OLAP, вводят понятие Java OLAP или Java OLAP (JOLAP) API.
JOLAP (Java OLAP) – новая, основанная на Java,
коллективная OLAP-API-инициатива, предназначенная для создания и управления
данными и метаданными на серверах OLAP. Основной разработчик – Hyperion Solutions. Другими
членами группы, определяющей предложенный API, являются компании IBM, Oracle и
др.
С одной стороны, JOLAP – спецификация,
предназначенная для создания и поддержания OLAP данных и метаданных на
корпоративной платформе Java. С другой стороны, можно говорить о сервере JOLAP,
например, Mondrian open source Java OLAP server 1.0.

3.1. MOLAP.
В многомерных OLAP-системах структура
куба хранится в многомерной базе данных. В той же базе данных хранятся
предварительно обработанные агрегаты и копии листовых значений. В связи с этим
все запросы к данным удовлетворяются многомерной системой баз данных, что
делает MOLAP-системы исключительно быстрыми.
Для загрузки MOLAP-системы требуется
дополнительное время на копирование в многомерную базу всех листовых данных.
Поэтому возникают ситуации, когда листовые данные MOLAP-системы оказываются
рассинхронизированными с данными в витрине данных. Таким образом, MOLAP-системы
вносят запаздывание в данные нижнего уровня иерархии.
Архитектура MOLAP требует большего
объема дискового пространства из-за хранения в многомерной базе копий листовых
данных. Но, несмотря на это, объем дополнительного пространства обычно не
слишком велик, поскольку данные в MOLAP хранятся исключительно эффективно.
MOLAP-серверы
используют для хранения и управления данными многомерные БД. При этом данные
хранятся в виде упорядоченных многомерных массивов. Такие массивы
подразделяются на гиперкубы и поликубы.
В
гиперкубе все хранимые в БД ячейки
имеют одинаковую мерность, т. е. находятся в максимально полном базисе
измерений.
В
поликубе каждая ячейка хранится с
собственным набором измерений, и все связанные с этим сложности обработки
перекладываются на внутренние механизмы системы.
Очевидно,
что физически данные, представленные в многомерном виде, хранятся в «плоских»
файлах. При этом куб представляется в виде одной плоской таблицы, в которую
построчно вписываются все комбинации членов всех измерений с соответствующими
им значениями мер (рисунок 1).

Рисунок 1. Представление многомерного массива
данных.
Можно
выделить следующие преимущества использования многомерных БД в OLAP-системах:
-
поиск и выборка данных осуществляются значительно быстрее, чем при многомерном
концептуальном взгляде на реляционную БД, т. к. многомерная база данных
денормализована и содержит заранее агрегированные показатели, обеспечивая
оптимизированный доступ к запрашиваемым ячейкам и не требуя дополнительных
преобразований при переходе от множества связанных таблиц к многомерной модели;
-
многомерные БД легко справляются с задачами включения в информационную модель
разнообразных встроенных функций, тогда как объективно существующие ограничения
языка SQL делают выполнение этих задач на основе реляционных БД достаточно
сложным, а иногда и невозможным.
К достоинствам MOLAP-систем можно также отнести следующие особенности:
- все данные хранятся в многомерных структурах, что существенно повышает скорость обработки запросов;
- доступны расширенные библиотеки для сложных функций оперативного анализа;
- обработка разреженных данных выполняется лучше, чем в ROLAP.
С
другой стороны, имеются также существенные недостатки:
-
за счет денормализации и предварительно выполненной агрегации объем данных в
многомерной БД, как правило, соответствует (по оценке Кодда) в 2,5... 100 раз
меньшему объему исходных детализированных данных;
-
в подавляющем большинстве случаев информационный гиперкуб является сильно
разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные
значения удается удалить только за счет выбора оптимального порядка сортировки,
позволяющего организовать данные в максимально большие непрерывные группы. Но
даже в этом случае проблема решается только частично. Кроме того, оптимальный с
точки зрения хранения разреженных данных порядок сортировки, скорее всего, не
будет совпадать с порядком, который чаще всего используется в запросах. Поэтому
в реальных системах приходится искать компромисс между быстродействием и
избыточностью дискового пространства, занятого базой данных;
- многомерные БД чувствительны к изменениям в
многомерной модели. Так при добавлении нового измерения приходится изменять
структуру всей БД, что влечет за собой большие затраты времени.
К недостатка MOLAP-систем можно отнести их следующие характеристики:
- данные куба «оторваны» от базовой таблицы;
- необходимы специальные инструменты для формирования кубов и их пересчёта в случае изменения базовых значений;
- сложно изменять измерения без повторной агрегации.
Представители
MOLAP-систем: Cognos
Powerplay, Oracle OLAP Option, Oracle Essbase, Microsoft Analysis Services.
На
основании анализа достоинств и недостатков многомерных БД можно выделить
следующие условия, при которых их использование является эффективным:
- объем исходных данных для анализа не слишком
велик (не более нескольких гигабайт), т. е. уровень агрегации данных достаточно
высок;
- набор информационных измерений стабилен;
-
время ответа системы на нерегламентированные запросы является наиболее
критичным параметром;
-
требуется широкое использование сложных встроенных функций для выполнения
кроссмерных вычислений над ячейками гиперкуба, в том числе возможность
написания пользовательских функций.
3.2. ROLAP.
ROLAP,
Relational OLAP – реляционный OLAP
В реляционных OLAP-системах структура
куба данных хранится в реляционной базе
данных. Меры самого нижнего уровня остаются в реляционной витрине данных,
служащей источником данных для куба. Предварительно обработанные агрегаты также
хранятся в реляционной таблице.
Когда человек, принимающий решение,
запрашивает значение меры для определенного набора элементов измерения,
ROLAP-система проверяет, указывают ли эти элементы на агрегат или на значение
самого нижнего уровня иерархии (листовое значение). Если указан агрегат, то
значение выбирается из реляционной таблицы. Если выбрано листовое значение, то
значение берется из витрины данных.
Благодаря реляционным таблицам,
архитектура ROLAP позволяет хранить большие объемы данных. Поскольку в
архитектуре ROLAP листовые значения берутся непосредственно из витрины данных,
то возвращаемые ROLAP-системой листовые значения всегда будут соответствовать
актуальному на данный момент положению дел. Другими словами, ROLAP-системы
лишены запаздывания в части листовых данных.
ROLAP-серверы
используют реляционные БД. По словам Кодда, «реляционные БД были есть и будут
наиболее подходящей технологией для хранения данных. Необходимость существует
не в новой технологии БД, а скорее в средствах анализа, дополняющих функции
существующих СУБД, и достаточно гибких, чтобы предусмотреть и автоматизировать
разные виды интеллектуального анализа, присущие OLAP».
В
настоящее время распространены две основные схемы реализации многомерного
представления данных с помощью реляционных таблиц: схема «звезда» (рисунок 2) и схема «снежинка»
(рисунок 3).
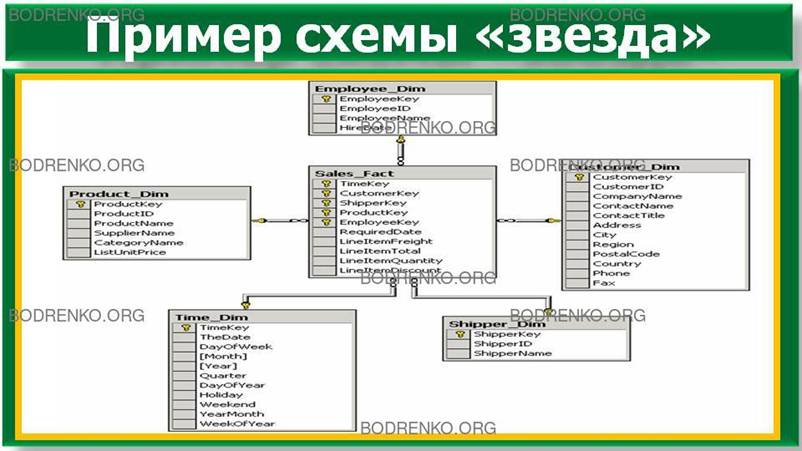
Рисунок 2. Пример схемы «звезда».
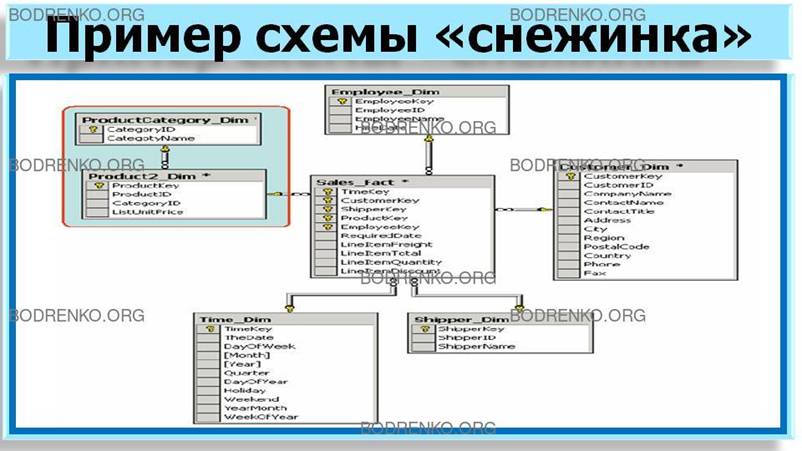
Рисунок З. Пример схемы «снежинка».
Основными
составляющими таких схем являются денормализованная таблица фактов (Fact Table)
и множество таблиц измерений (Dimension Tables).

ТАБЛИЦА
ФАКТОВ.
Таблица фактов, как правило, содержит сведения об
объектах или событиях, совокупность которых будет в дальнейшем анализироваться.
Обычно
говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся:
- факты, связанные с транзакциями
(Transaction facts). Они основаны на отдельных событиях (типичными примерами
которых являются телефонный звонок или снятие денег со счета с помощью
банкомата);
- факты, связанные с «моментальными снимками»
(Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в
определенные моменты времени, например на конец дня или месяца. Типичными
примерами таких фактов являются объем продаж за день или дневная выручка;
-
факты, связанные с элементами документа
(Line-item facts). Основаны на том или ином документе (например, счете за товар
или услуги) и содержат подробную информацию об элементах этого документа
(например, количестве, цене, проценте скидки);
- факты, связанные с событиями
или состоянием объекта (Event or state facts). Представляют
возникновение события без подробностей о нем (например, просто факт продажи или
факт отсутствия таковой без иных подробностей).

Таблица
фактов, как правило, содержит уникальный составной ключ, объединяющий первичные
ключи таблиц измерений. При этом как ключевые, так и некоторые не ключевые поля
должны соответствовать измерениям гиперкуба. Чаще всего это целочисленные значения либо
значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч
или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания,
как правило, невыгодно — лучше поместить их в меньшие по объему таблицы
измерений. При этом как ключевые, так и некоторые неключевые поля должны
соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно
или несколько числовых полей, на основании которых в дальнейшем будут получены
агрегатные данные.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно
более подробные данные, т. е. соответствующие членам нижних уровней иерархии соответствующих
измерений.
ПРИМЕР.
Например,
для многомерного анализа предпочтительнее взять за основу факты продажи товаров
отдельным заказчикам, а не суммы продаж для разных стран — последние все равно
будут вычислены OLAP-средством.
В
таблице фактов нет никаких сведений о том, как группировать записи при
вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или
клиентов, но отсутствует информация о том, к какой категории относится данный
продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем
используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
ТАБЛИЦЫ ИЗМЕРЕНИЙ.
Таблицы измерений содержат неизменяемые
либо редко изменяемые данные. В подавляющем большинстве случаев эти данные
представляют собой по одной записи для каждого члена нижнего уровня иерархии в
измерении. Таблицы измерений также содержат как минимум одно описательное поле
(обычно с именем члена измерения) и, как правило, целочисленное ключевое поле
(обычно это суррогатный ключ) для однозначной идентификации члена измерения.
Если будущее измерение, основанное на данной таблице измерений, содержит
иерархию, то таблица измерений также может содержать поля, указывающие на
«родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица
измерений может содержать и поля, указывающие на «прародителей», и иных
«предков» в данной иерархии (это обычно характерно для сбалансированных
иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в
исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна
находиться в отношении «один-ко-многим» с таблицей фактов.
Отметим,
что скорость роста таблиц измерений должна быть незначительной по сравнению со
скоростью роста таблицы фактов; например, новая запись в таблицу измерений,
характеризующую товары, добавляется только при появлении нового товара, не
продававшегося ранее.
Одно измерение куба может содержаться
как в одной таблице (в том числе и при наличии нескольких уровней иерархии),
так и в нескольких связанных таблицах, соответствующих различным уровням
иерархии в измерении.
Если каждое измерение содержится в одной таблице, такая
схема хранилища данных носит название «звезда» (star schema).
Пример такой схемы приведен на рисунке 4.
Рисунок
4. Пример схемы «звезда».
Если же хотя бы одно измерение содержится в нескольких
связанных таблицах, такая схема хранилища данных носит название «снежинка»
(snowflake schema).
Дополнительные таблицы измерений в
такой схеме, обычно соответствующие верхним уровням иерархии измерения и
находящиеся в соотношении «один ко многим» в главной таблице измерений,
соответствующей нижнему уровню иерархии, иногда называют консольными таблицами
(outrigger table). Пример схемы «снежинка» приведен на рисунке 5.
Рисунок
5. Пример схемы «снежинка».
Отметим, что даже при наличии
иерархических измерений с целью
повышения скорости выполнения запросов к хранилищу данных нередко предпочтение
отдается схеме «звезда».
Однако не все хранилища данных
проектируются по двум приведенным выше схемам. Так, довольно часто вместо
ключевого поля для измерения, содержащего данные типа «дата», и соответствующей
таблицы измерений сама таблица фактов может содержать ключевое поле типа «дата».
В этом случае соответствующая таблица измерений просто отсутствует.
В случае несбалансированной иерархии в
схему «снежинка» также следует вносить коррективы. В этом случае обычно в
таблице измерений присутствует связь, аналогичная соответствующей связи в
оперативной базе данных.
Еще один пример отступления от правил —
наличие нескольких разных иерархий для одного и того же измерения. Типичные
примеры таких иерархий — иерархии для календарного и финансового года (при
условии, что финансовый год начинается не с 1 января), или с различными
способами группировки членов измерения (например, группировать товары можно по
категориям, а можно и по компаниям-поставщикам). В этом случае таблица
измерений содержит поля для всех возможных иерархий с одними и теми же членами
нижнего уровня, но с разными членами верхних уровней.
Как мы уже отмечали выше, таблица измерений может
содержать поля, не имеющие отношения к иерархиям и представляющие собой просто
дополнительные атрибуты членов измерений (member properties). Иногда такие
атрибуты могут быть использованы при анализе данных. В сложных задачах с
иерархическими измерениями имеет смысл обратиться к расширенной схеме
«снежинка» (Snowflake Schema). В этих случаях отдельные таблицы фактов
создаются для возможных сочетаний уровней обобщения различных измерений (см.
рисунок 5). Это позволяет добиться лучшей производительности, но часто приводит
к избыточности данных и к значительным усложнениям в структуре базы данных, в
которой оказывается огромное количество таблиц фактов.
Увеличение
числа таблиц фактов в базе данных определяется не только множественностью
уровней различных измерений, но и тем обстоятельством, что в общем случае факты
имеют разные множества измерений. При абстрагировании от отдельных измерений
пользователь должен получать проекцию максимально полного гиперкуба, причем
далеко не всегда значения показателей в ней должны являться результатом
элементарного суммирования. Таким образом, при большом числе независимых
измерений необходимо поддерживать множество таблиц фактов, соответствующих
каждому возможному сочетанию выбранных в запросе измерений, что также приводит
к неэкономному использованию внешней памяти, увеличению времени загрузки данных
в БД схемы «звезды» из внешних источников и сложностям администрирования.
Использование
реляционных БД в OLAP-системах имеет следующие достоинства:
-
в большинстве случаев корпоративные хранилища данных реализуются средствами
реляционных СУБД, и инструменты ROLAP позволяют производить анализ
непосредственно над ними. При этом размер хранилища не является таким критичным
параметром, как в случае MOLAP;
-
в случае переменной размерности задачи, когда изменения в структуру измерений
приходится вносить достаточно часто, ROLAP-системы с динамическим
представлением размерности являются оптимальным решением, т. к. в них такие
модификации не требуют физической реорганизации БД;
-
реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и
хорошие возможности разграничения прав доступа.
К достоинствам этого класса систем можно также отнести:
- возможность использования ROLAP с хранилищами данных и различными OLTP-системами;
- возможность манипулирования большими объемами данных;
- объем данных могут ограничивать только лежащие в основе ROLAP системы реляционных баз данных, подход ROLAP сам по себе не ограничивает объем данных;
- безопасность и администрирование обеспечивается реляционными СУБД.
Недостатки ROLAP:
- получение агрегатов и листовых данных происходит медленнее, чем, например, в MOLAP и HOLAP;
- функциональность систем ограничивается возможностями SQL, так как аналитические запросы пользователя транслируются в SQL-операторы выборки;
- сложно пересчитывать агрегированные значения при изменениях начальных данных;
сложно поддерживать таблицы агрегатов.
Главный
недостаток ROLAP по сравнению с многомерными СУБД – меньшая производительность.
Для обеспечения производительности, сравнимой с MOLAP, реляционные системы
требуют тщательной проработки схемы базы данных и настройки индексов, т. е.
больших усилий со стороны администраторов БД. Только при использовании схем
типа «звезда» производительность хорошо настроенных реляционных систем может
быть приближена к производительности систем на основе многомерных баз данных.
Пионером ROLAP был продукт Metaphor
компании Metaphor Computer Systems, появившийся в 80-х годах. Также выделим MetaCube
фирмы IBM Informix. На современном этапе развития ROLAP отметим Microsoft
Analysis Services.
3.3. HOLAP.
HOLAP (Hybrid OLAP) – гибридный OLAP.
В гибридных OLAP сочетаются черты ROLAP и MOLAP, отсюда и
название – гибридный. В моделях HOLAP используются преимущества и
минимизируются недостатки обеих архитектур.
В HOLAP-системах структура куба и
предварительно обработанные агрегаты хранятся в многомерной базе данных. Это
позволяет обеспечить быстрое извлечение агрегатов из структур MOLAP. Значения
нижнего уровня иерархии в HOLAP остаются в реляционной витрине данных, которая
служит источником данных для куба.
HOLAP не требует копирования листовых
данных из витрины, хотя это и ведет к увеличению времени доступа при обращении
к листовым данным. Данные в витрине доступны аналитику сразу после обновления.
Таким образом, HOLAP-системы не вносят запаздывания в работу с данными нижнего
уровня иерархии. По сути, HOLAP жертвует скоростью доступа к листовым данным
ради устранения запаздывания при работе с ними и ускорения загрузки данных. В
связи с этим HOLAP проигрывает по скорости MOLAP.
HOLAP-серверы
используют гибридную архитектуру, которая объединяет технологии ROLAP и MOLAP.
В отличие от MOLAP (которая работает лучше, когда данные более-менее плотные),
серверы ROLAP показывают лучшие параметры в тех случаях, когда данные довольно
разрежены. Серверы HOLAP применяют подход ROLAP для разреженных областей многомерного
пространства и подход MOLAP – для плотных областей. Серверы HOLAP разделяют
запрос на несколько подзапросов, направляют их к соответствующим фрагментам
данных, комбинируют результаты, а затем предоставляют результат пользователю.
Таким образом, к достоинствам гибридного
подхода HOLAP
можно отнести комбинирование технологии ROLAP для разреженных данных и MOLAP
для плотных областей, а к недостаткам – необходимость поддерживания MOLAP и
ROLAP.
Представители HOLAP-систем:
Microsoft Analysis Services, MicroStrategy, IBM DB2 OLAP Server, Sagent Holos.
3.4. DROLAP (A
Dense-Region Based Approach to OLAP).
DROLAP (A
Dense-Region Based Approach to OLAP) – OLAP, основанный на плотных областях.
По утверждениям авторов данного
подхода, DROLAP превосходит ROLAP и MOLAP в эффективности управления
пространством и обработки запросов. DROLAP заимствует преимущества ROLAP и
MOLAP и комбинирует их для поддержки высокой скорости исполнения запросов и
эффективности использования памяти.
Основой DROLAP системы является использование плотных областей (dense
regions) в кубах данных. Для этого используется алгоритм EDEM (Efficient Dense
Region Mining). Также подход DROLAP лучше управляет не только дисковым
пространством, но и кластеризованными многомерными данными. Модель
DROLAP создавалась в рамках исследовательского проекта.
3.5. Тематические модели OLAP-систем.
Развитие прикладных информационных
систем, появление новых типов данных заставляют поставщиков разрабатывать новые
подходы к оперативной аналитической обработке данных. Рассмотрим тематические
модели OLAP.
SOLAP (Spatial OLAP) – пространственный OLAP.
Пространственная аналитическая
обработка предназначена для изучения пространственных данных. В этой области
объединяются понятия из существенно различающихся сфер знаний географических
информационных систем и OLAP. Модель SOLAP разработана для интерактивного и
быстрого анализа больших объемов данных, хранящихся в пространственных базах
данных.
Представители: JMap Spatial OLAP, GeoMondrian.
SeOLAP (Semantic
OLAP) – семантический OLAP.
Модель SeOLAP ориентирована на
семантические методы поиска и извлечения данных и знаний. Область SeOLAP пока
разработана недостаточно, хотя в последние годы это направление явно привлекает
внимание исследователей.
Семантический OLAP нацелен на решение
таких проблем, как семантическое управление для предотвращения «взрыва данных»,
преодоление «семантических разрывов OLAP» и т.д.
Модель SeOLAP подходит для
семантического управления данными, а также аналитической обработки данных
Semantic Web (Семантический веб).
Mobile OLAP – OLAP для мобильных устройств.
Функциональность модели Mobile OLAP
рассматривается относительно беспроводных сетей или мобильных устройств.
Реализации Mobile OLAP позволяют работать с OLAP-данными и приложениями
удаленно через мобильные устройства.
Представители: CubeView.

ВЫВОДЫ.
1.
Для анализа информации наиболее удобным способом ее представления является
многомерная модель или гиперкуб, ребрами которого являются измерения. Это
позволяет анализировать данные сразу по нескольким измерениям, т. е. выполнять
многомерный анализ.
2.
Измерение — это последовательность значений одного из анализируемых параметров.
Измерения могут представлять собой иерархическую структуру. На пересечениях
измерений находятся данные, количественно характеризующие анализируемые факты —
меры.
3.
Над многомерной моделью — гиперкубом могут выполняться операции: среза,
вращения, консолидации и детализации. Эти операции и многомерную модель
реализуют OLAP-системы.
4.
OLAP (On-Line Analytical Processing) — технология оперативной аналитической
обработки данных. Это класс приложений, предназначенных для сбора, хранения и
анализа многомерных данных в целях поддержки принятия решений.
5.
Для определения OLAP-систем Кодд разработал 12 правил, позднее дополнил еще
шесть и разбил 18 правил на четыре группы: основные особенности, специальные
особенности, особенности представления отчетов и управление измерениями.
6. В 1995 году Пендсон и Крит на основании
правил Кодда разработали тест FASMI, определив OLAP как «Быстрый Анализ
Разделяемой Многомерной Информации».
7.
Архитектура OLAP-системы включает OLAP-сервер и OLAP-клиент. OLAP-сервер может
быть реализован на основе многомерных БД (MOLAP), реляционных БД (ROLAP) или
сочетания обеих моделей (HOLAP).
8.
Достоинствами MOLAP являются высокая производительность и простота
использования встроенных функций.
9.
Достоинствами ROLAP являются возможность работы с существующими реляционными
БД, более экономичное использование ресурсов и большая гибкость при добавлении
новых измерений.
10. Актуальность OLAP-технологий
обусловлена их практической значимостью для анализа больших объемов данных. В
связи с этим имеется проблема выбора оптимальных схем хранения и обработки OLAP
данных. Рассмотренная классификация моделей OLAP обеспечивает такое
представление. Например, для анализа геопространственных данных пригодна модель
Spatial OLAP, для мобильных пользователей – Mobile OLAP.
Такая классификация полезна
пользователям, желающим получить представление о существующих моделях OLAP, а
также о представителях той или иной модели.
СПИСОК РЕКОМЕНДОВАННОЙ ЛИТЕРАТУРЫ.
[1] Барсегян А. А., Куприянов М. С. , Степаненко В. В., Холод И. И. Методы и модели анализа данных: OLAP и Data Mining. – СПб.: БХВ-Петербург, 2004. - 336 с.
[2] Елманова Н., Федоров А. Введение в OLAP-технологии Microsoft. - М.: Диалог-МИФИ, 2002. - 272 с.

[3] Кудрявцев Ю.А. OLAP технологии: обзор решаемых задач и исследований // Бизнес-информатика. – 2008. №1. – С. 66-70.
[4] Фоменко Е.Ю. Хранилища данных. Анализ данных: Курс
лекций. - М.: Ф-т ВМиК МГУ им. М.В. Ломоносова, 2007.
[5] Хоббс Л., Хилсон С., Лоуэнд Ш. Oracle9iR2: разработка и эксплуатация хранилищ баз данных. Учебно-справочное изданиеы. Пер. С англ. - М.: КУДИЦ-ОБРАЗ, 2004. – 592 с.
